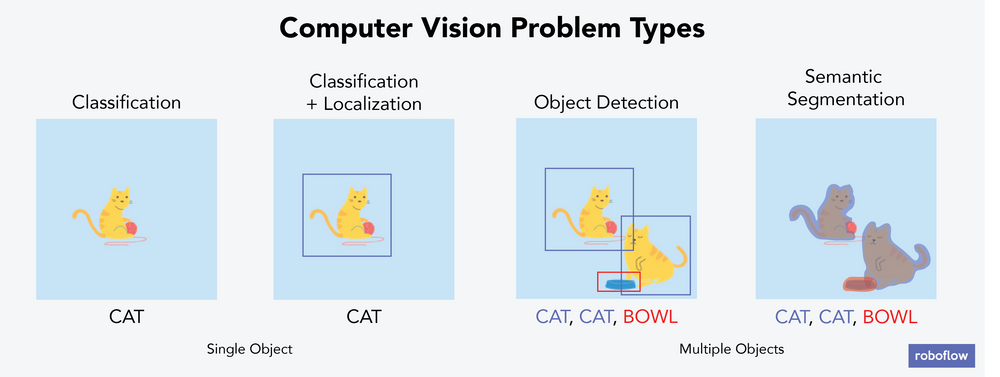
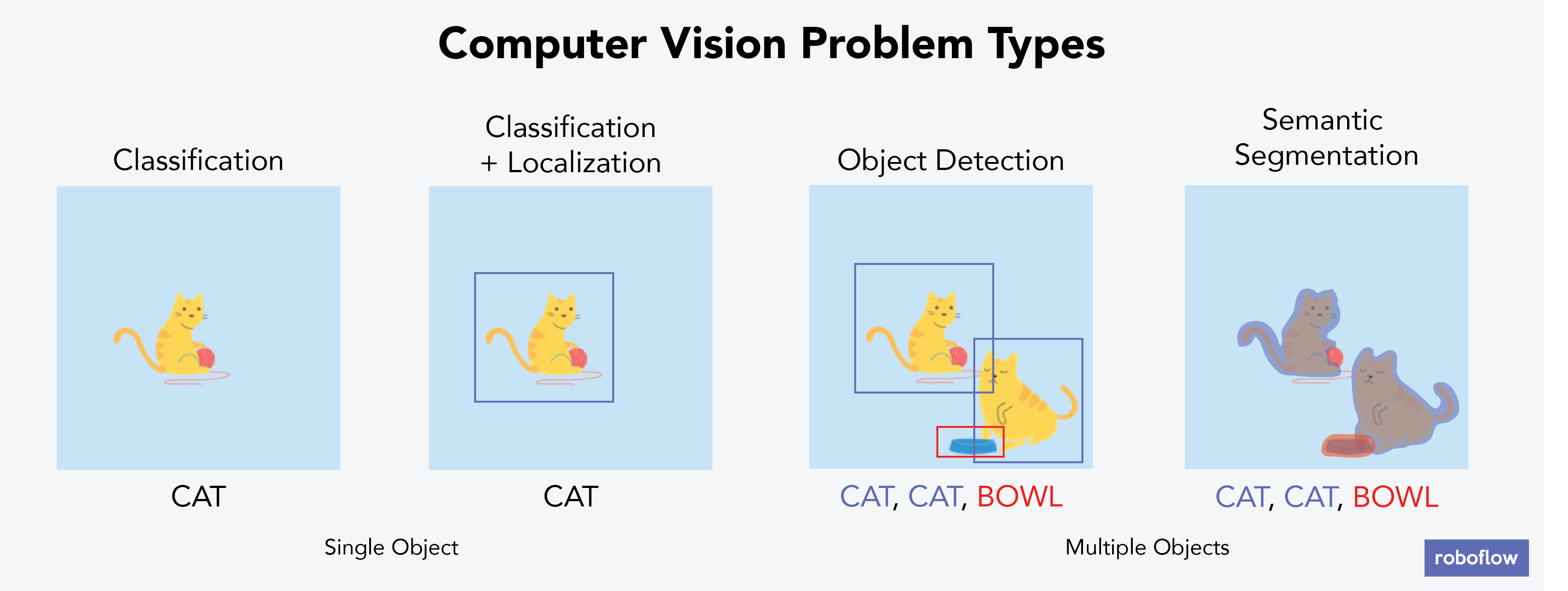
Computer vision problems require annotated datasets.
Object detection problems, specifically, require that items within frame are bounded in labeled annotations.
As object detection has developed, different file formats to describe object annotations have emerged. This creates frustrating situations where teams dedicate time to converting from one annotation format to another rather than focusing on higher value tasks – like improving deep learning model architectures.
A data scientist spending time converting between annotation formats is like to an author spending time converting Word documents to PDFs.
The most common annotation formats have emerged from challenges and amassed datasets. As machine learning researchers leveraged these datasets to build better models, the format of their annotation formats became unofficial standard protocol(s).
In this post we will give you the code necessary to convert between two of the most common formats: VOC XML and COCO JSON.
Want to skip the coding?
Roboflow generates COCO JSON, VOC XML, and others from any computer vision annotation format in three clicks. Jump to the bottom of this post to see how.
PASCAL VOC XML
PASCAL (Pattern Analysis, Statistical modelling and ComputAtional Learning) is a Network of Excellence funded by the European Union. From 2005 - 2012, PASCAL ran the Visual Object Challenge (VOC).
PASCAL annually released object detection datasets and reported benchmarks. (An aggregated PASCAL VOC dataset is available here.)
PASCAL VOC annotations were released in an XML format, where each image has an accompanying XML file describing the bounding box(es) contained in frame.
For example, in the BCCD dataset for blood cells detection, a single XML annotation example looks like as follows:
<annotation>
<folder>JPEGImages</folder>
<filename>BloodImage_00000.jpg</filename>
<path>/home/pi/detection_dataset/JPEGImages/BloodImage_00000.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>640</width>
<height>480</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>WBC</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>260</xmin>
<ymin>177</ymin>
<xmax>491</xmax>
<ymax>376</ymax>
</bndbox>
</object>
...
<object>
...
</object>
</annotation>
Note a few key things: (1) the image file that is being annotated is mentioned as a relative path (2) the image metadata is included as width, height, and depth (3) bounding box pixels positions are denoted by the top left-hand corner and bottom right-hand corner as xmin, ymin, xmax, ymax.
COCO JSON
The Common Objects in Context (COCO) dataset originated in a 2014 paper Microsoft published. The dataset "contains photos of 91 objects types that would be easily recognizable by a 4 year old." There are a total of 2.5 million labeled instances across 328,000 images.
Given the sheer quantity and quality of data open sourced, COCO has become a standard dataset for testing and proving state of the art performance in new models. (The dataset is available here.)
COCO annotations were released in a JSON format. Unlike PASCAL VOC where each image has its own annotation file, COCO JSON calls for a single JSON file that describes a set of collection of images.
Moreover, the COCO dataset supports multiple types of computer vision problems: keypoint detection, object detection, segmentation, and creating captions. Because of this, there are different formats for the task at hand. This post focuses on object detection.
A COCO JSON example annotation for object detection looks like as follows:
{
"info": {
"year": "2020",
"version": "1",
"description": "Exported from roboflow.ai",
"contributor": "",
"url": "https://app.roboflow.ai/datasets/bccd-single-image-example/1",
"date_created": "2020-01-30T23:05:21+00:00"
},
"licenses": [
{
"id": 1,
"url": "",
"name": "Unknown"
}
],
"categories": [
{
"id": 0,
"name": "cells",
"supercategory": "none"
},
{
"id": 1,
"name": "RBC",
"supercategory": "cells"
},
{
"id": 2,
"name": "WBC",
"supercategory": "cells"
}
],
"images": [
{
"id": 0,
"license": 1,
"file_name": "0bc08a33ac64b0bd958dd5e4fa8dbc43.jpg",
"height": 480,
"width": 640,
"date_captured": "2020-02-02T23:05:21+00:00"
}
],
"annotations": [
{
"id": 0,
"image_id": 0,
"category_id": 2,
"bbox": [
260,
177,
231,
199
],
"area": 45969,
"segmentation": [],
"iscrowd": 0
},
{
"id": 1,
"image_id": 0,
"category_id": 1,
"bbox": [
78,
336,
106,
99
],
"area": 10494,
"segmentation": [],
"iscrowd": 0
},
{
"id": 2,
"image_id": 0,
"category_id": 1,
"bbox": [
63,
237,
106,
99
],
"area": 10494,
"segmentation": [],
"iscrowd": 0
},
...
]
}
Note a few key things here: (1) there is information on dataset itself and its license (2) all labels included are defined as categories (3) bounding boxes are defined as the x, y coordinates of the upper-left hand corner followed by the bounding box's width and height.
Converting VOC XML to COCO JSON
Popular annotation tools like Roboflow, LabelImg, VoTT, and CVAT provide annotations in Pascal VOC XML. Some models like ImageNet call for Pascal VOC. Others, like Mask-RCNN, call for COCO JSON annotated images.
To convert from one format to another, you can write (or borrow) a custom script or use a tool like Roboflow.
Using a Python Script to Convert Pascal VOC XML to COCO JSON
GitHub user (and Kaggle Master) yukkyo created a script the Roboflow team has forked and slightly modified the repository for ease of use here:

The full Python script is as follows:
import os
import argparse
import json
import xml.etree.ElementTree as ET
from typing import Dict, List
from tqdm import tqdm
import re
def get_label2id(labels_path: str) -> Dict[str, int]:
"""id is 1 start"""
with open(labels_path, 'r') as f:
labels_str = f.read().split()
labels_ids = list(range(1, len(labels_str)+1))
return dict(zip(labels_str, labels_ids))
def get_annpaths(ann_dir_path: str = None,
ann_ids_path: str = None,
ext: str = '',
annpaths_list_path: str = None) -> List[str]:
# If use annotation paths list
if annpaths_list_path is not None:
with open(annpaths_list_path, 'r') as f:
ann_paths = f.read().split()
return ann_paths
# If use annotaion ids list
ext_with_dot = '.' + ext if ext != '' else ''
with open(ann_ids_path, 'r') as f:
ann_ids = f.read().split()
ann_paths = [os.path.join(ann_dir_path, aid+ext_with_dot) for aid in ann_ids]
return ann_paths
def get_image_info(annotation_root, extract_num_from_imgid=True):
path = annotation_root.findtext('path')
if path is None:
filename = annotation_root.findtext('filename')
else:
filename = os.path.basename(path)
img_name = os.path.basename(filename)
img_id = os.path.splitext(img_name)[0]
if extract_num_from_imgid and isinstance(img_id, str):
img_id = int(re.findall(r'\d+', img_id)[0])
size = annotation_root.find('size')
width = int(size.findtext('width'))
height = int(size.findtext('height'))
image_info = {
'file_name': filename,
'height': height,
'width': width,
'id': img_id
}
return image_info
def get_coco_annotation_from_obj(obj, label2id):
label = obj.findtext('name')
assert label in label2id, f"Error: {label} is not in label2id !"
category_id = label2id[label]
bndbox = obj.find('bndbox')
xmin = int(bndbox.findtext('xmin')) - 1
ymin = int(bndbox.findtext('ymin')) - 1
xmax = int(bndbox.findtext('xmax'))
ymax = int(bndbox.findtext('ymax'))
assert xmax > xmin and ymax > ymin, f"Box size error !: (xmin, ymin, xmax, ymax): {xmin, ymin, xmax, ymax}"
o_width = xmax - xmin
o_height = ymax - ymin
ann = {
'area': o_width * o_height,
'iscrowd': 0,
'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id,
'ignore': 0,
'segmentation': [] # This script is not for segmentation
}
return ann
def convert_xmls_to_cocojson(annotation_paths: List[str],
label2id: Dict[str, int],
output_jsonpath: str,
extract_num_from_imgid: bool = True):
output_json_dict = {
"images": [],
"type": "instances",
"annotations": [],
"categories": []
}
bnd_id = 1 # START_BOUNDING_BOX_ID, TODO input as args ?
print('Start converting !')
for a_path in tqdm(annotation_paths):
# Read annotation xml
ann_tree = ET.parse(a_path)
ann_root = ann_tree.getroot()
img_info = get_image_info(annotation_root=ann_root,
extract_num_from_imgid=extract_num_from_imgid)
img_id = img_info['id']
output_json_dict['images'].append(img_info)
for obj in ann_root.findall('object'):
ann = get_coco_annotation_from_obj(obj=obj, label2id=label2id)
ann.update({'image_id': img_id, 'id': bnd_id})
output_json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for label, label_id in label2id.items():
category_info = {'supercategory': 'none', 'id': label_id, 'name': label}
output_json_dict['categories'].append(category_info)
with open(output_jsonpath, 'w') as f:
output_json = json.dumps(output_json_dict)
f.write(output_json)
def main():
parser = argparse.ArgumentParser(
description='This script support converting voc format xmls to coco format json')
parser.add_argument('--ann_dir', type=str, default=None,
help='path to annotation files directory. It is not need when use --ann_paths_list')
parser.add_argument('--ann_ids', type=str, default=None,
help='path to annotation files ids list. It is not need when use --ann_paths_list')
parser.add_argument('--ann_paths_list', type=str, default=None,
help='path of annotation paths list. It is not need when use --ann_dir and --ann_ids')
parser.add_argument('--labels', type=str, default=None,
help='path to label list.')
parser.add_argument('--output', type=str, default='output.json', help='path to output json file')
parser.add_argument('--ext', type=str, default='', help='additional extension of annotation file')
args = parser.parse_args()
label2id = get_label2id(labels_path=args.labels)
ann_paths = get_annpaths(
ann_dir_path=args.ann_dir,
ann_ids_path=args.ann_ids,
ext=args.ext,
annpaths_list_path=args.ann_paths_list
)
convert_xmls_to_cocojson(
annotation_paths=ann_paths,
label2id=label2id,
output_jsonpath=args.output,
extract_num_from_imgid=True
)
if __name__ == '__main__':
main()The repository linked above includes a full working example based on the BCCD dataset.
To reproduce it, call the bash script make_bccd_cocojson.sh. COCO JSON annotations for each dataset (test.json, train.json, trainval.json, val.json) in the sample folder are outputted.
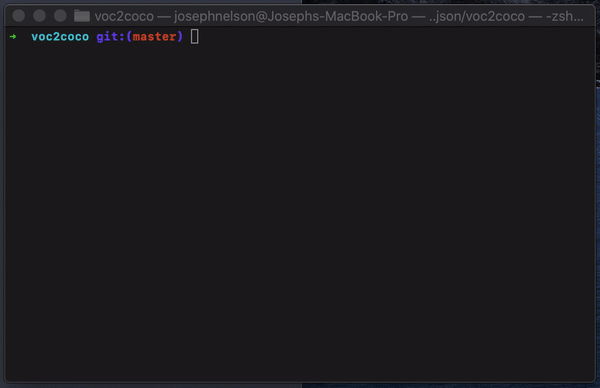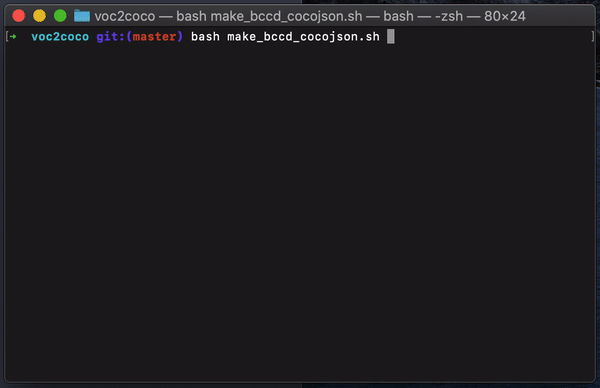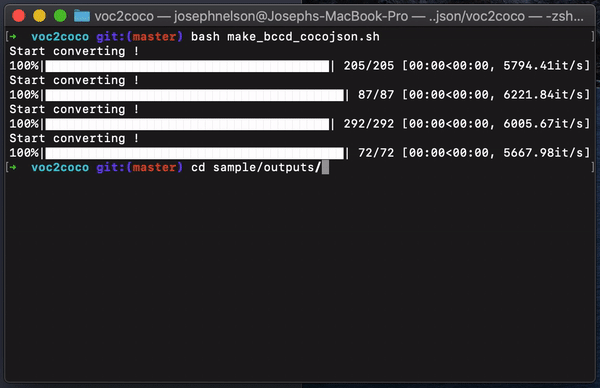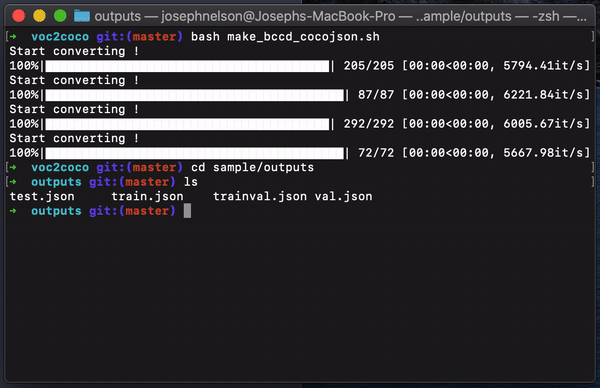
To reuse this script on your own example, your file structure must match that of the example repository.
Using Roboflow to Convert Pascal VOC XML to COCO JSON
Roboflow enables conversion from Pascal VOC XML to COCO JSON (or vice versa) with just a few clicks.
In fact, you can use Roboflow to convert from nearly any format (CreateML JSON, YOLO Darknet TXT, LabelMe, SuperAnnotate, Scale AI, Labelbox, Supervisely, and dozens more) to any other annotation format, even to generate your TFRecords. It's free for datasets up to 1000 images.
Roboflow is the "universal converter" for your images and annotations: upload in any annotation format, and export to any other.
To do so, create a Roboflow account, click "Create Dataset" and give your dataset a name and describe all your annotation groups (for example, the BCCD dataset would be "cells").
Drag and drop your images and annotations into the upload area. Roboflow then checks your annotations to be sure they're logical (e.g. no bounding boxes are out-of-frame).
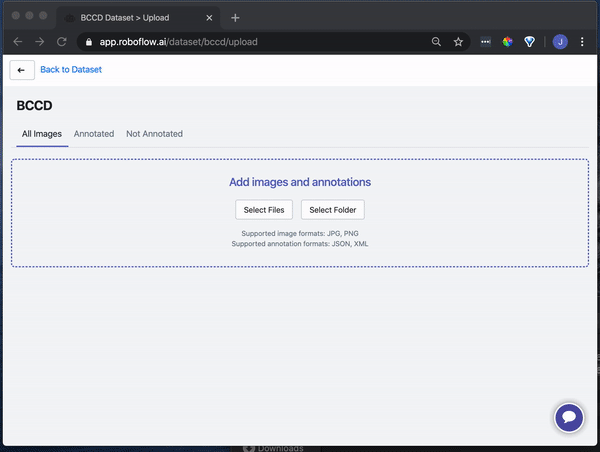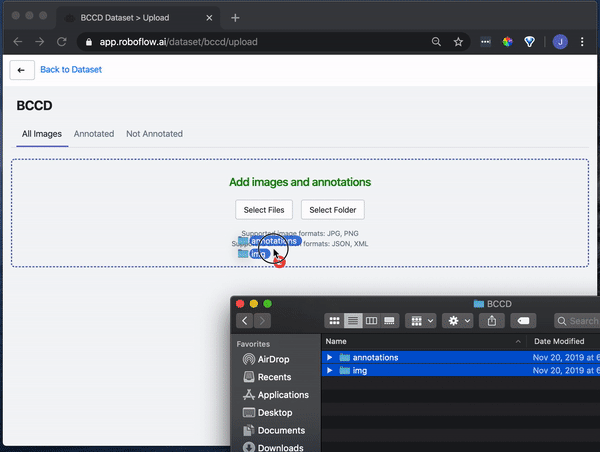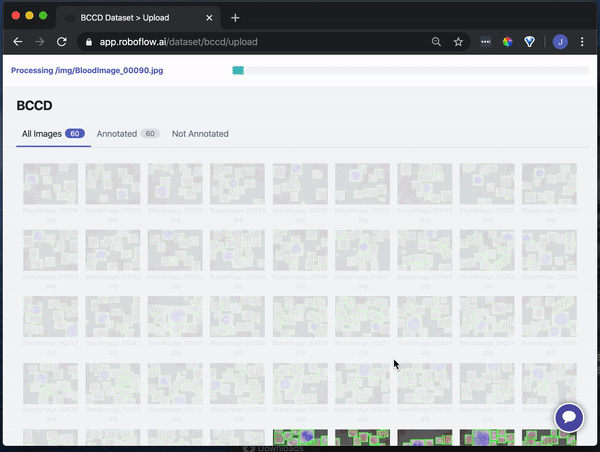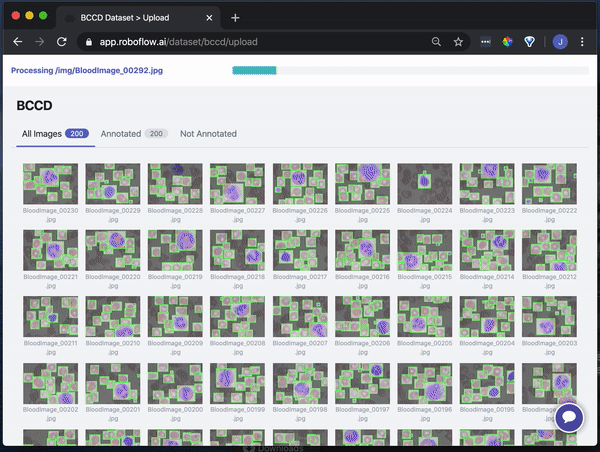
Once your dataset is checked and processed, click "Start Uploading" in the upper right-hand corner.
Once your dataset is uploaded, you're directed to the main "Modify Dataset" page. Here, you can apply preprocessing and/or augmentation steps if you like. Note that "auto-orient" and "resize" are on by default.
To convert our raw images as-is, turn these off and generate an export.
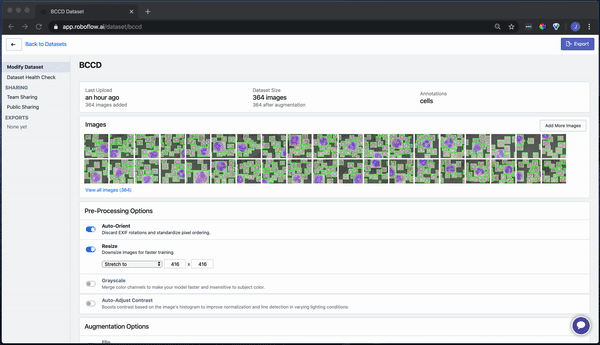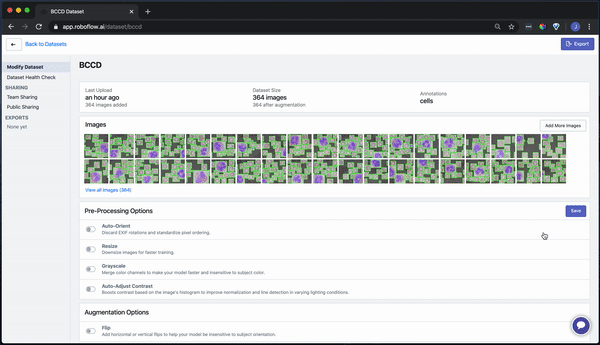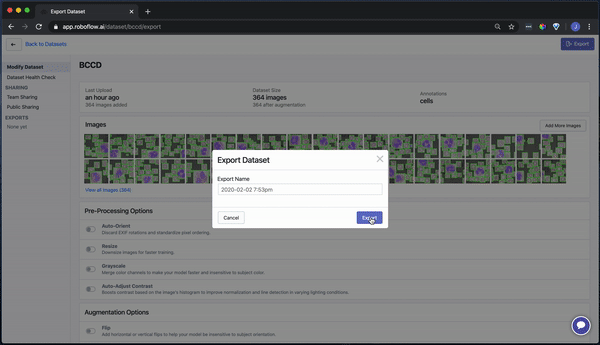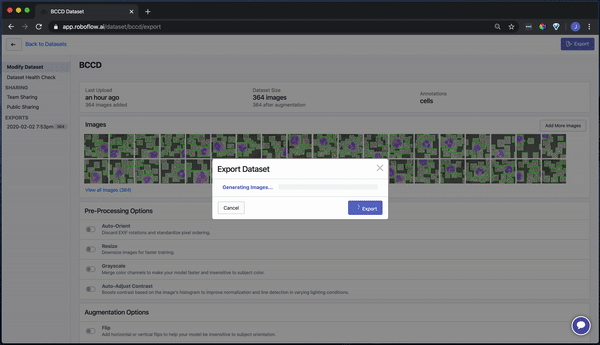
Our images are ready to be downloaded. You can download a zip locally to your computer, or you can create a code snippet to download them into your Jupyter notebook with wget.
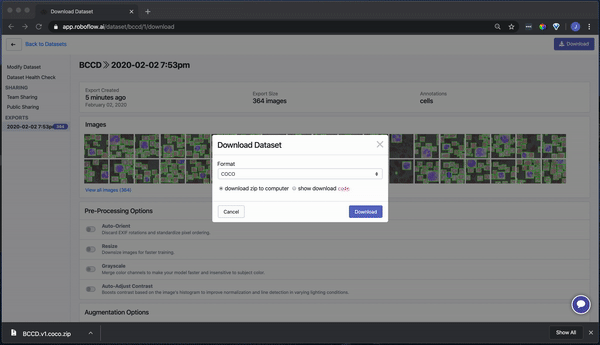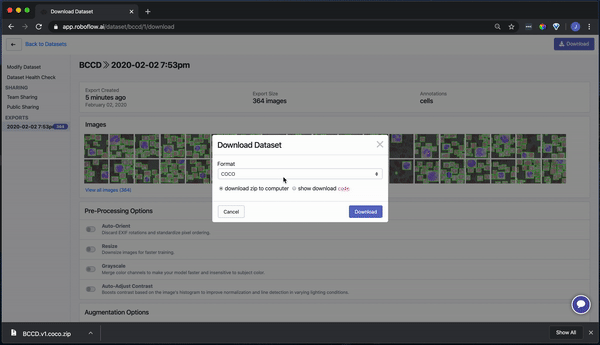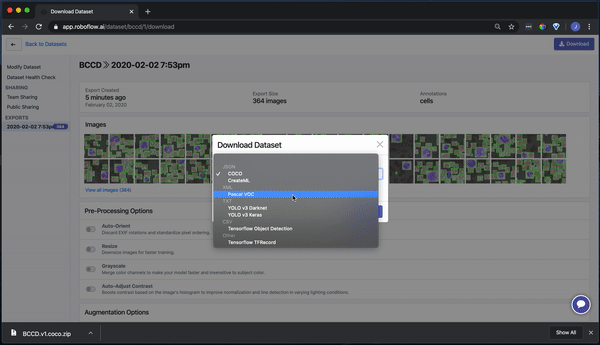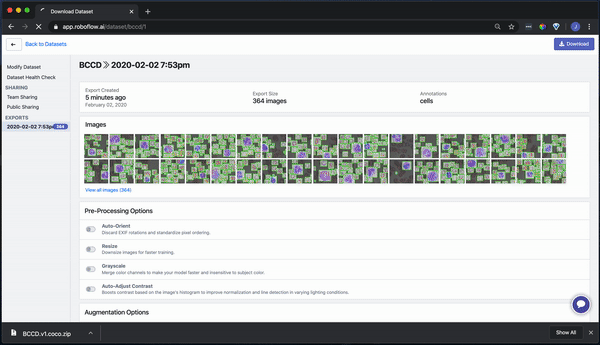
Roboflow supports a wide array of export formats:
- PASCAL VOC XML
- CreateML JSON
- TuriCreate JSON
- COCO JSON
- TFRecord
- YOLO Darknet
- YOLOv3 Keras
- And many, many more.
With Roboflow, you can even create your train, validations, and test sets – and generate COCO JSON annotations for each. It makes it super easy to experiment with different computer vision frameworks and models.
Happy building!