
YOLOv3 is known to be an incredibly performant, state-of-the-art model architecture: fast, accurate, and reliable. So how does the "new kid on the block," EfficientDet, compare?
Without spoilers, we were surprised by these results.
NOTE: YOLO v5 has been published after this publication and we have found better results there. Please see our post on how to train YOLOv5 on your own data.
Our Scope
In this post, we compare the modeling approach, training time, model size, inference time, and downstream performance of two state of the art image detection models - EfficientDet and YOLOv3. Both models are implemented with easy to use, practical implementations that could be deployed by any developer. To learn how to train these models, see our tutorial on how to train EfficientDet and our tutorial on how to train YOLOv3. Both of these implementations are in PyTorch and export weights that can be ported into an application for inference.
- For your custom data set, you need only change two lines of code where your data set is imported in COCO json for EfficientDet and YOLOv3 Darknet for the YOLOv3 PyTorch implementation.
- If you would like: skip right to the Colab notebook comparing YOLOv3 and EfficientDet
- While we were writing this, YOLOv4 was released and we will be comparing YOLOv4 with EfficientDet in future posts.
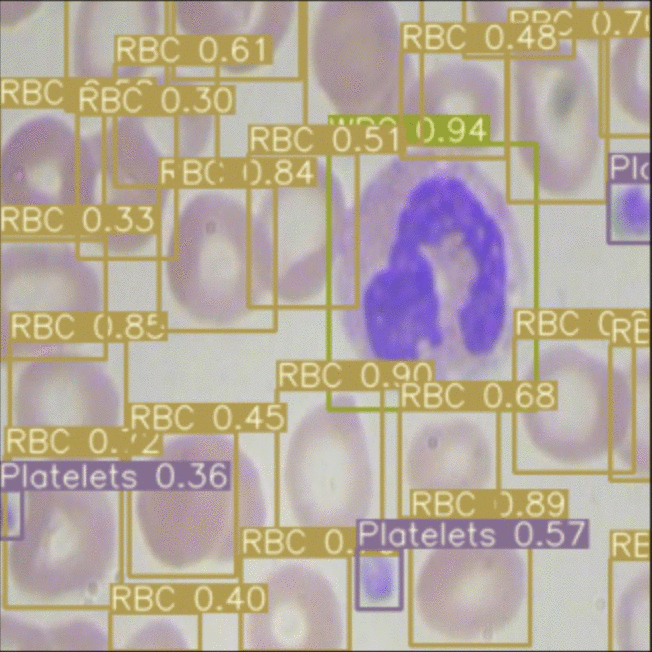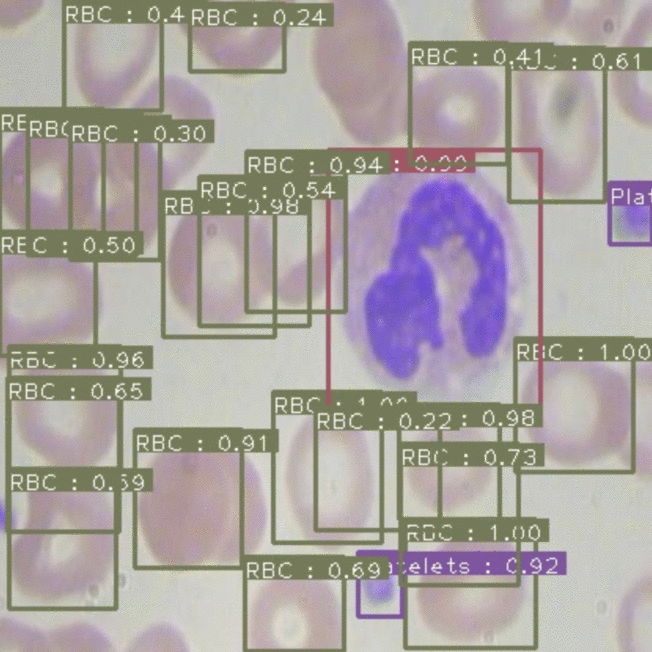
Disclaimer: Our work here exists beyond the bounds of academic peer-review. It is meant as a quick measure of how feasible each of these models are to deploy in a production computer vision setting, today, with a practical implementation that you can use in a Colab notebook. Things like inference time can be measured more exactly and more properly configured under ideal deployment conditions.
A Brief Introduction to EfficientDet
EfficientDet has recently gained popularity as the state of the art model for image detection, because it is both performant and fast relative to other image detection models. Previously, YOLOv3 had been the go to model for image detection.
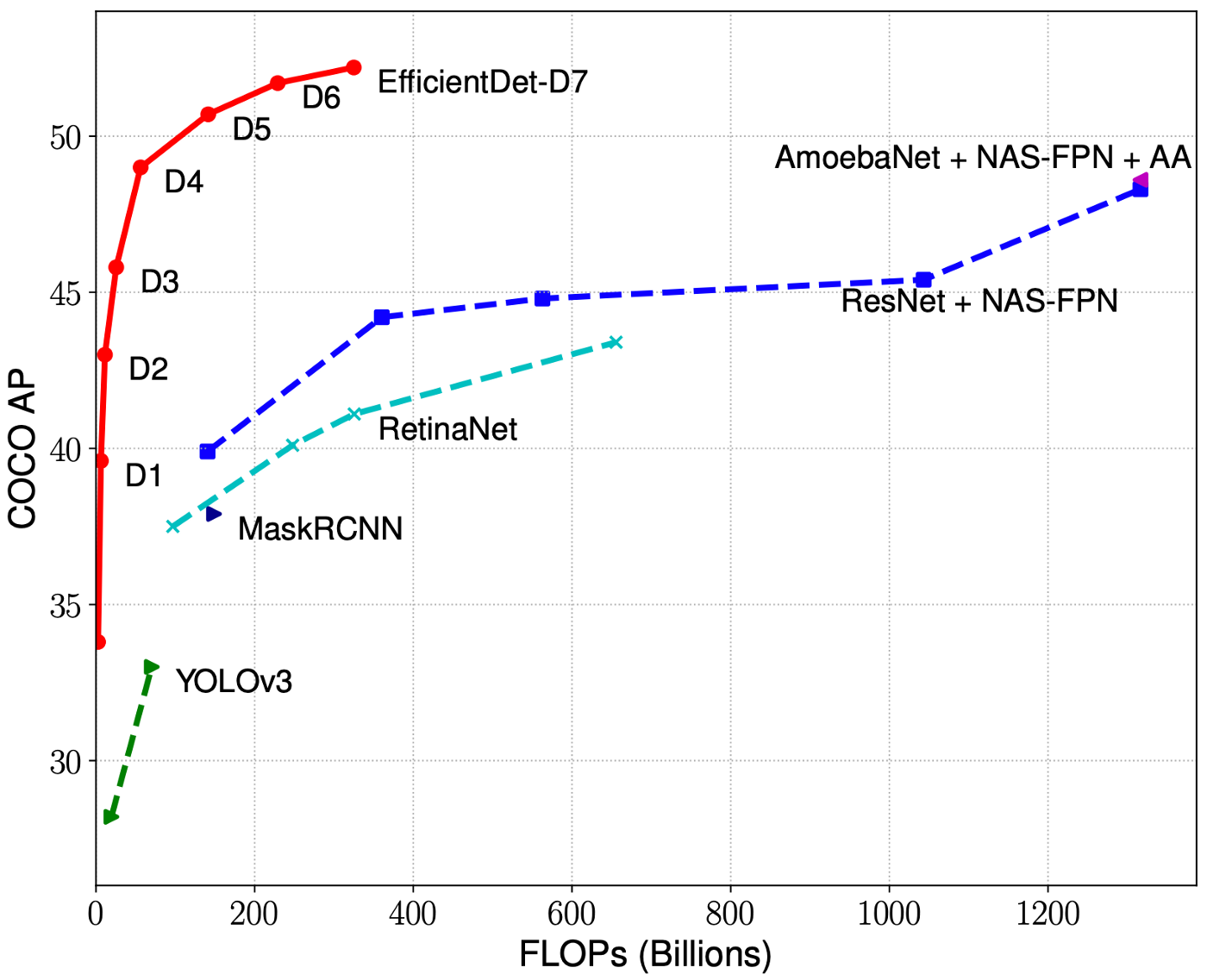
On the COCO dataset for image detection, EfficientDet is shown to have the best performance among peer models relative to model size. (See our prior post for a comprehensive breakdown EfficientDet.) COCO contains 80 object classes that span a range of vision semantics and is considered the gold standard for image detection tasks. The idea is - if the model can master COCO, then it will generalize well to new image detection tasks, provided the right amount of supervised data for that new task.
In this post, we put that COCO generalization hypothesis to the test and we find that both models do very well in generalizing to new tasks. We test both models on the tasks of identifying chess pieces and identifying red/white blood cells. We provide a comparison of their performance in terms of training time, model size, inference time, and mAP.
EfficientDet and YOLOv3 Model Architectures
YOLO made the initial contribution to frame the object detection problem as a two step problem to spatially separate bounding boxes as a regression problem and then tag classify those bounding boxes into the expected class labels. It turned out that this approach was very effective for making image detection predictions near real time. In subsequent iterations the training framework, data set inputs, and detection scale were improved in YOLO, YOLOv2, and YOLOv3 (and as we are writing these lines writing YOLOv4!).
EfficientDet preserves the task framing as bounding box regression and class label classification, but carefully implements specific areas of the network. First, for the convolutional neural network backbone, EfficientDet uses EfficientNet, a state of the art ConvNet build by the Google Brain team. Second, EfficientDet uses neural architecture search to find out exactly how to combine the EfficientNet feature layers. Third, the EfficientDet paper studies how to efficiently scale each portion of the network (size of ConvNet, number of feature fusion layers, input resolution, and class/box network) through search. See here for our in depth discussion of the EfficientDet model in summary.
Evaluation Tasks
We evaluate the two models in the context of identifying chess pieces in computer vision and identifying red/white bloodcells in computer vision. (Both datasets are hosted publicly on Roboflow.) The chess dataset contains roughly 300 images with 3000 annotations. The blood cell dataset contains roughly 400 images with 5000 class annotations.
For each of the models, data is imported from Roboflow (after data upload) in two formats - COCO JSON for EfficientDet and YOLOv3 Darknet for the YOLOV3 PyTorch implementation model. Roboflow makes it extremely easy to receive both of these data download links and input into the model's train/val/test data directories. This allows you to get straight to training and research without having to worry about data manipulations and scrubbing.
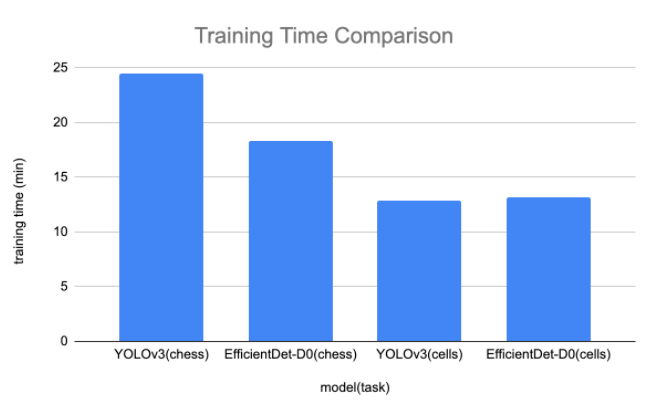
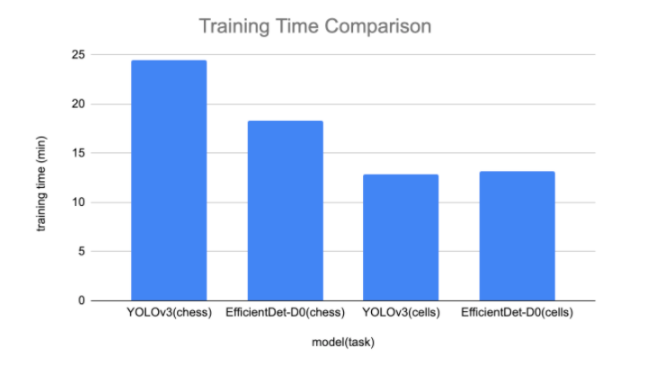
Training Time Comparison
To train each model on chess, we pass the dataset through the model for 100 epochs. We settled on 100 epochs based on validation set improvement beginning to level off for this task. We find that EfficientDet trains slightly faster (18.3 minutes) than YOLOv3 (24.5 minutes) with our implementations. This is promising because the software libraries around EfficientDet will continue to improve and this initial training time lead will drop over time.
To train each model on blood cells, we pass the dataset through the model for 100 epochs. We find that EfficientDet trains slightly faster than YOLOv3.
The number of epochs will vary for your custom dataset and we encourage you to play around with finding the optimal spot to train these models for comparison.
Model Size Comparison
We compare the size of each model in terms of file size of the weights. We expect EfficientDet-D0 to have a smaller file size given that it contains far fewer parameters (4 million) compared to YOLOv3 (65 million). Our model implementations output trained weights in the form of .pth and .onnx for EfficientDet and the .pt for EfficientDet. Below are the resulting model file sizes:
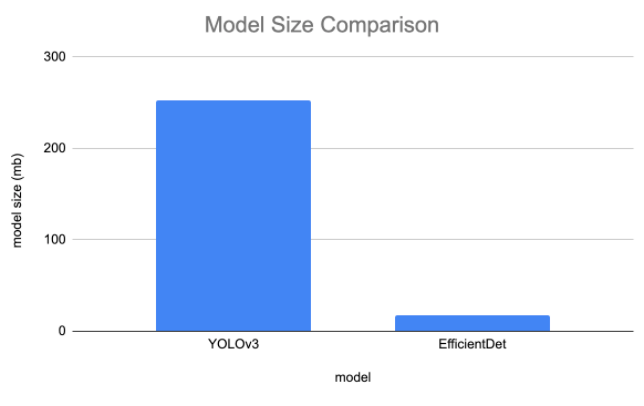
To store, EfficientDet-D0 is truly tiny - and this is including the EfficientNet ConvNet backbone.
Inference Time Comparison

In order to measure inference, we attempt to narrow down to the exact portion of each implementation that takes the network input and inferences to the network output. This hopefully removes some of the bias around how images are processed and inference annotations are saved. That being said, we again expect EfficientDet implementation to be improved as the model gains popularity and implementations improve. We pass our test set through inference and measure the inference time for each image. Then, we average the inference times to create a stable estimate. Results below:
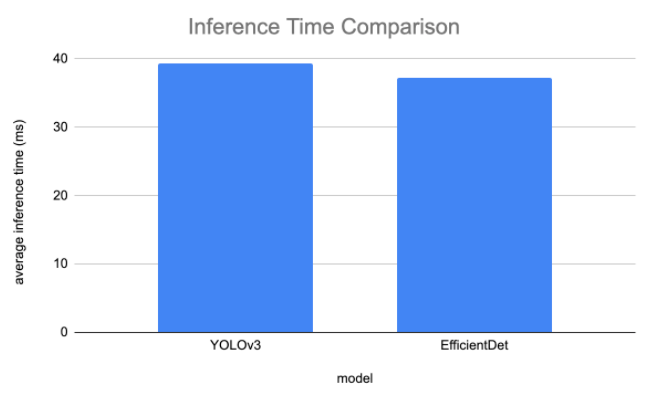
The inference times were closer than we expected, but EfficientDet is still the clear winner. And again, we expect that gap to widen with improved implementations.
Accuracy Comparison
To estimate the model's comparable accuracy we calculate the mAP metric on our test sets for both datasets. The mAP estimates the model's performance across confidence values, allowing the model to trade off precision for recall as it decreases in confidence. Here we plot the mAP for both tasks of chess and blood cells.
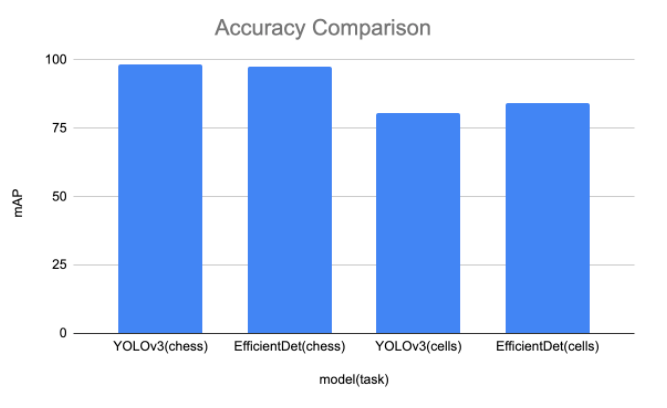
The takeaways here are that both models do extremely well on chess, with YOLOv3 doing slightly better. However, with performance in the high 90s - this could be an artifact of just how wide the margins were drawn in annotation. For blood cells, EfficientDet slightly outperforms YOLOv3 - with both models picking up the task quite well.
Conclusion 🏆
We find that a realistic implementation of EfficientDet outperforms YOLOv3 on two custom image detection tasks in terms of training time, model size, inference time, and accuracy. We implemented these tests in a YOLOv3 versus EfficienDet notebook that you can quickly use for your own use case. 🚀