We seek to build computer vision models that generalize to as many real world situations as we can, even when we cannot anticipate them. It's a bit of a catch-22: build deep learning models that predict a world that you may have not anticipated.
But that's what is at the crux of preventing overfitting. Unintentionally, we build models that best predict our training data, but not the real world (or the test set).
Thus, deliberately introducing noise is one way to help hold our models accountable. We seek to have them learn the patterns of the training data – not memorize. The difference is subtle. But models (including convolutional neural networks) are far more brittle than humans are in their ability to reason, so simple perturbations in data can yield serious unintended consequences.
What is Noise? Why Care?
Noise is deliberately altering pixels to be different than what they may should have represented. Old-fashioned films are famous for having speckles black and white pixels present where they should not be. This is noise!
Noise is one kind of imperfection that can be particularly frustrating for machines versus human understanding. While humans can easily ignore noise (or fit it within appropriate context), algorithms struggle. This is the root of so-called adversarial attacks where small, human-imperceptible pixel changes can dramatically alter a neural network's ability to make an accurate prediction.
Researchers from Arizona State University considered the impact various image imperfections have on classification models. Of the the methods tested, blurring and noise had the most adverse effect on top-1 and top-5 accuracy classification.
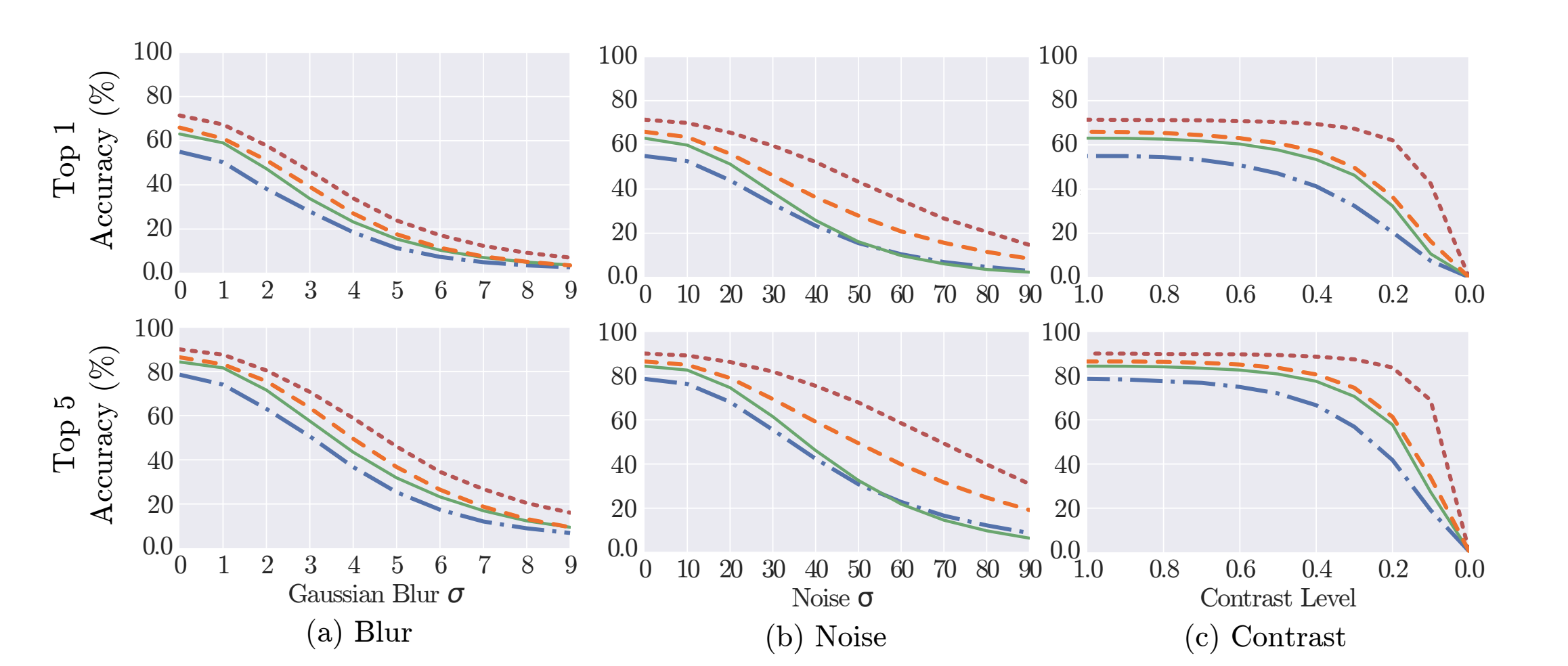
While other imperfections like JPEG compression and contrast took their toll only when significantly increased, noise and gaussian blurring showed near immediate smoothing on tested models (VGG16, GoogleNet, VGG-CNN-S, Caffe Reference).
Noise Use Cases
So, when should we make noise?
Noise could be a preprocessing technique – applied to all images before a model learns and makes inferences – or an augmentation technique, where it is applied only to images in the training set for strategic variation.
In most instances, noise is best suited for augmentation: we seek to increase variability of some images for the purposes of training to mitigate adversarial attacks and avoid overfitting, but we don't seek to induce noise into our validation and testing sets as well.
Implementing Noise
There are multiple types of noise we can add when processing signals. (For example, white noise is a consistent level of noise added uniformly.)
For the purposes of image processing, we often create salt-and-pepper noise – that is, randomly change some pixels to completely white or completely black. In some cases, we may speckle noise (uniformly add), only add white pixels (salt), or only add black pixels (pepper).

Scikit-image does have implementations of many forms of noise. It's best practice to vary the amount of noise a given image receives so that all images are not provided the same amount of noise.
Commonly, the amount of noise added to an image is dictated by the proportion of the number of pixels to be replaced. (A default value is often 5 percent.)
Roboflow also supports adding noise to images. A user dictates the maximum amount of pixels any given image may have replaced with noise (say, n). Then, each image in a dataset has anywhere from zero to n amount of noise added sampled from a uniform distribution.

Roboflow also keeps a log of how each image was varied so you can easily see what level of noise may be most problematic.
Happy building!