
On January 31st, 2024, Tencent’s AI Lab released YOLO-World (access code on Github), a real-time, open-vocabulary object detection model. YOLO-World is a zero-shot model, which means you can run object detection without any training.
Follow our open source guide on how to use YOLO-World if you are interested in trying the model.
YOLO-World was designed to solve a limitation of existing zero-shot object detection models: speed. Whereas other state-of-the-art models use Transformers, a powerful but typically slower architecture, YOLO-World uses the faster CNN-based YOLO architecture.
In this guide, we are going to discuss what YOLO-World is, the recent history of zero-shot object detection, and how the model performs according to the YOLO-World paper.
From Fixed-Class Object Detectors to YOLO-World
Traditional Object Detectors
Traditional object detection models, such as Faster R-CNN, SSD, and YOLO, are designed to identify objects within a predetermined set of categories defined by their training datasets. For instance, models trained on the COCO dataset are limited to 80 categories.
This limitation restricts their applicability to scenarios that match the training data's scope. Extending or altering the set of recognizable classes necessitates retraining or fine-tuning the model on a custom dataset tailored to the new categories.
Open-Vocabulary Object Detection
As a response to the limitations of fixed-vocabulary detectors, open-vocabulary object detection (OVD) models aim to recognize objects beyond the predefined categories. Early attempts in this direction, such as GLIP and Grounding DINO, focused on leveraging large-scale image-text data to expand the training vocabulary, enabling the detection of novel objects. All you have to do is prompt the model and specify what objects you are looking for.

However, they tend to be larger and more computationally intensive, requiring simultaneous encoding of images and texts for prediction. This approach, while powerful, introduces latency that can hinder practical applications. See this guide if you want to try GroundingDINO.
What is YOLO-World?
YOLO-World, introduced in the research paper “YOLO-World: Real-Time Open-Vocabulary Object Detection”, shows a significant advancement in the field of open-vocabulary object detection by demonstrating that lightweight detectors, such as those from the YOLO series, can achieve strong open-vocabulary performance. This is particularly noteworthy for real-world applications where efficiency and speed are crucial, like edge applications.
YOLO World has grounding capabilities and can understand the context in a prompt to provide detections. You do not need to train the model on a particular class because the model has been trained using image-text pairs and grounded images. The model has learned how to take an arbitrary prompt – for example, “person wearing a white shirt” – and use that for detection.
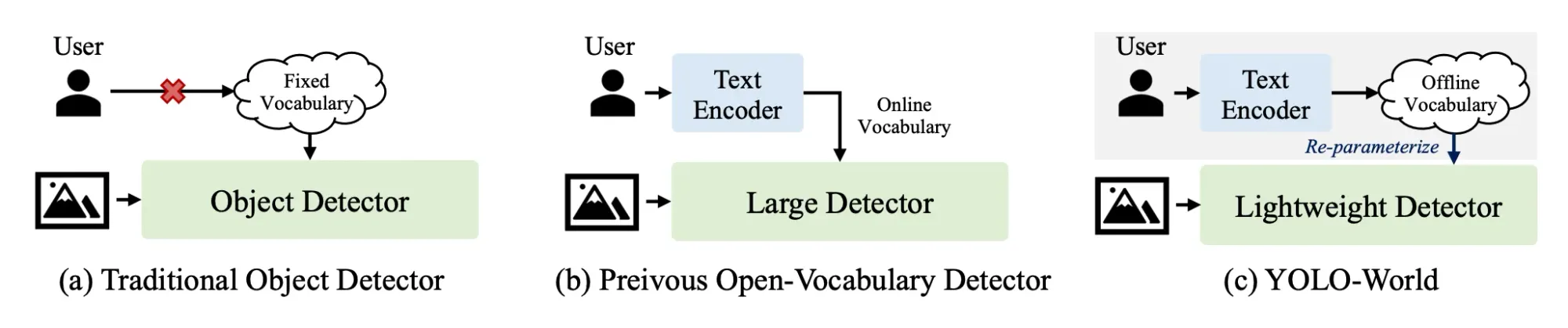
YOLO-World introduces the "prompt-then-detect" paradigm, a novel approach that avoids the need for real-time text encoding. Instead, it allows for the generation of prompts by users, which are then encoded into an offline vocabulary.
By pre-encoding a series of user-generated prompts into an offline vocabulary, the model bypasses the need for real-time text encoding, enabling quicker and more adaptable detection.
Unlike traditional methods, which rely on a fixed set of predefined categories, or earlier open-vocabulary approaches that encode user prompts in real-time (online vocabulary), YOLO-World introduces a more efficient alternative.
This approach significantly reduces computational overhead [Figure 1.], allowing for dynamic adjustment of the detection vocabulary to meet varying needs without sacrificing performance, thus enhancing the model's utility in real-world applications.
YOLO-World Architecture
YOLO-World's architecture consists of three key elements:
- YOLO detector - based on Ultralytics YOLOv8; extracts the multi-scale features from the input image.
- Text Encoder - Transformer text encoder pre-trained by OpenAI’s CLIP; encodes the text into text embeddings.
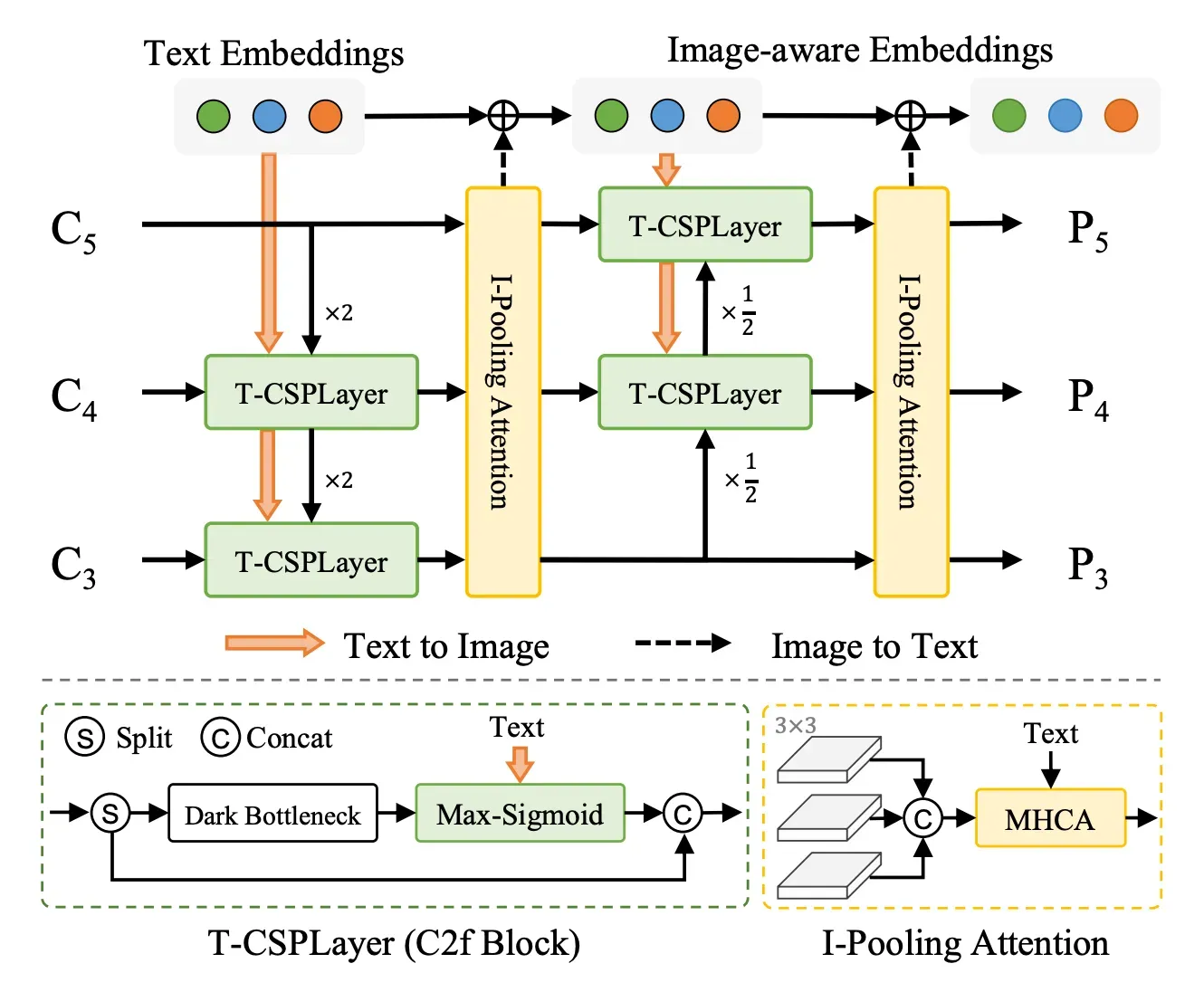
- Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) - performs multi-level cross-modality fusion between image features and text embeddings.
The fusion between image features and text embeddings is implemented via:
- Text-guided Cross Stage Partial Layer (T-CSPLayer): Built on top of the C2f layer, used in the YOLOv8 architecture, by adding text guidance into multi-scale image features. This is achieved through the Max Sigmoid Attention Block, which computes attention weights based on the interaction between text guidance and spatial features of the image. These weights are then applied to modulate the feature maps, enabling the network to focus more on areas relevant to the text descriptions.
- Image-Pooling Attention: Optimizes text embeddings with visual context by applying max pooling to multi-scale image features, thus distilling them into 27 patch tokens that encapsulate essential regional data. These tokens are then transformed through a process involving queries derived from text embeddings and keys and values from image patches, to compute scaled dot-product attention weights.
YOLO-World Performance
YOLO-World follows on from a series of zero-shot object detection models released last year. These models, capable of identifying an object without fine-tuning, are typically slow and resource-intensive.
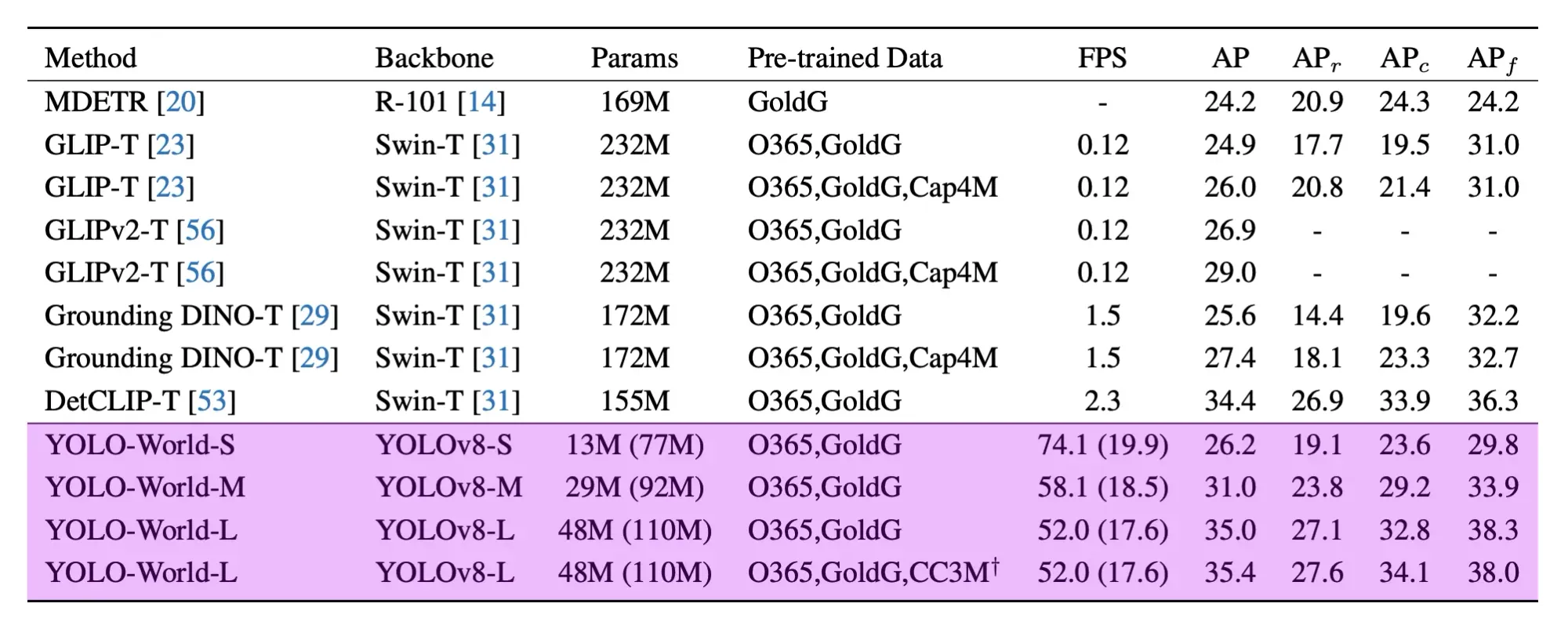
YOLO-World provides three models: small with 13M (re-parametrized 77M), medium with 29M (re-parametrized 92M), and large with 48M (re-parametrized 110M) parameters.
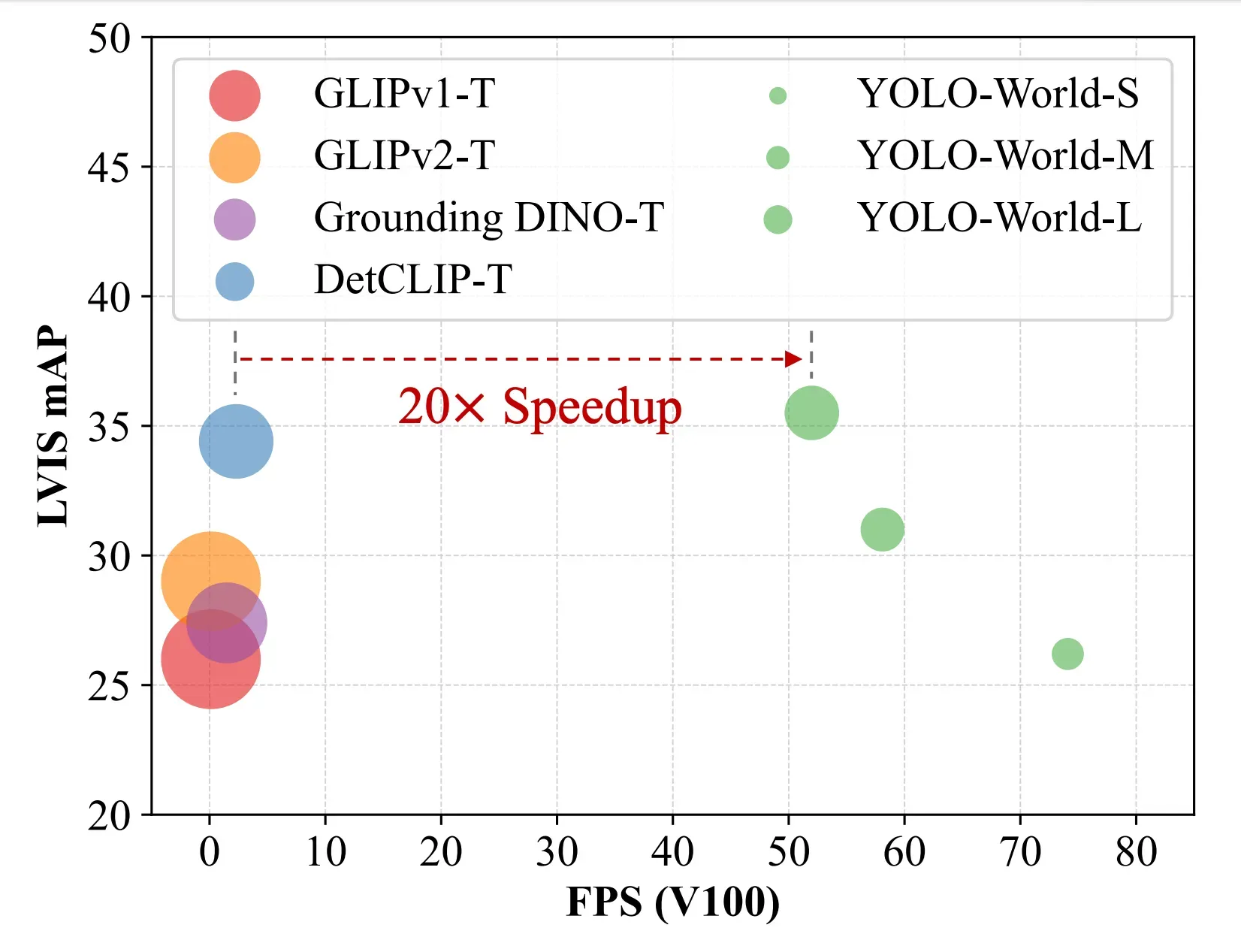
The YOLO-World team benchmarked the model on the LVIS dataset and measured their performance on the V100 without any performance acceleration mechanisms like quantization or TensorRT.
According to the paper YOLO-World reached between 35.4 AP with 52.0 FPS for the large version and 26.2 AP with 74.1 FPS for the small version. While the V100 is a powerful GPU, achieving such high FPS on any device is impressive.
Using YOLO-World
Follow our open source guide on how to use YOLO-World if you are interested in running the model on your own or you can try the model on Hugging Face and dive into the model code on GitHub.
When you deploy a YOLO-World model, you specify a custom vocabulary that you want to use. Then, embeddings will be calculated that are used during model inference. Embeddings are passed through a Vision-Language Path Aggregation Network (RepVL-PAN) network developed for the model. The result is then used to apply region-text matching for use in detection.
You can use YOLO-World in a variety of ways:
- Real-time object detection and tracking on edge devices
- Video processing and analytics
- Auto-labeling data for custom vision model training
While these tasks are achieved with custom vision models today, using YOLO-World you may be able to create applications without needing to train a model. You will be able to get vision applications running in production faster by avoiding the time it takes to label data and train a model.
You are to deploy YOLO-World in Roboflow Inference, an edge deployment solution trusted by large enterprises to deploy YOLO models in production and Roboflow will be publishing an Autodistill module to use YOLO World to auto-label your data in a few lines of code.
Conclusion
YOLO-World is an important step in making open-vocabulary object detection faster, cheaper, and widely available. Maintaining nearly the same accuracy, YOLO-World is 20x faster and 5x smaller than leading zero-shot detectors.
This opens the way to use cases that so far have been impossible like open-vocabulary video processing or deployment of open-vocabulary detectors on the edge.