
Training large image transformers comes with heavy compute requirements - enter the Gaudi2 from Habana Labs, an Intel company.
In this post, through the Intel Disruptor program, we will walk through a tutorial of how we can scale up large scale image classification training using the vision transformer ViT and eight Gaudi2 HPUs running on the Intel Developer Cloud.
A Quick Intro on the Vision Transformer (ViT)
Transformers have made a significant impact in the world of AI research and practice - powering development in LLMs and landing in the computer vision world with the vision transformer (ViT) architecture.
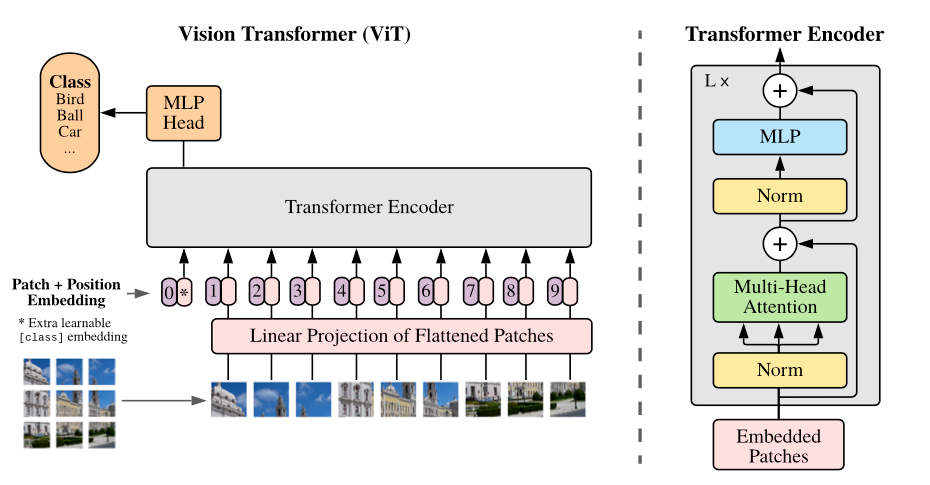
The ViT architecture treats a series of patches of image pixels like the language transformers treat text tokens, allowing the sequence based transformer architecture to be applied to images.
We'll be scaling up ViT training for classification in this post.
A Quick Intro to Gaudi2 HPUs
Habana Labs, an Intel company, has been pioneering the development of a new type of AI acceleration hardware known as the Gaudi HPU. Gaudi1 HPUs became popular on the AWS DL1 instances where you can spin up an instance with 8 Gaudi HPUs. Recently, Intel has released Gaudi2 HPUs on their Intel Developer Cloud, which are benchmarked to be a bit stronger than NVIDIA A100 GPUs on deep learning tasks.
The Intel Habana HPUs are operated by SynapseAI®, a software layer on top of the Gaudi hardware akin to cuda. SynapseAI® has bindings for both PyTorch and TensorFlow.
In this post, we put the Gaudi2s to the test of scaling up ViT training across on a multi-HPU Gaudi2 machine.
Without further ado.
Configuring Our Gaudi2 Machine
Once we've SSH'd into our Gaudi2 Machine (available on Intel's Developer Cloud) - we check our hardware with hl-smi
devcloud@idc330:~$ hl-smi
+-----------------------------------------------------------------------------+
| HL-SMI Version: hl-1.10.0-fw-43.2.0.0 |
| Driver Version: 1.10.0-416d95e |
|-------------------------------+----------------------+----------------------+
| AIP Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | AIP-Util Compute M. |
|===============================+======================+======================|
| 0 HL-225 N/A | 0000:19:00.0 N/A | 0 |
| N/A 35C N/A 74W / 600W | 768MiB / 98304MiB | 2% N/A |
|-------------------------------+----------------------+----------------------+
| 1 HL-225 N/A | 0000:b3:00.0 N/A | 0 |
| N/A 33C N/A 59W / 600W | 768MiB / 98304MiB | 0% N/A |
|-------------------------------+----------------------+----------------------+
| 2 HL-225 N/A | 0000:b4:00.0 N/A | 0 |
| N/A 35C N/A 53W / 600W | 768MiB / 98304MiB | 0% N/A |
|-------------------------------+----------------------+----------------------+
| 3 HL-225 N/A | 0000:cc:00.0 N/A | 0 |
| N/A 35C N/A 75W / 600W | 768MiB / 98304MiB | 3% N/A |
|-------------------------------+----------------------+----------------------+
| 4 HL-225 N/A | 0000:cd:00.0 N/A | 0 |
| N/A 33C N/A 46W / 600W | 768MiB / 98304MiB | 0% N/A |
|-------------------------------+----------------------+----------------------+
| 5 HL-225 N/A | 0000:1a:00.0 N/A | 0 |
| N/A 37C N/A 69W / 600W | 768MiB / 98304MiB | 2% N/A |
|-------------------------------+----------------------+----------------------+
| 6 HL-225 N/A | 0000:43:00.0 N/A | 0 |
| N/A 36C N/A 70W / 600W | 768MiB / 98304MiB | 2% N/A |
|-------------------------------+----------------------+----------------------+
| 7 HL-225 N/A | 0000:44:00.0 N/A | 0 |
| N/A 35C N/A 46W / 600W | 768MiB / 98304MiB | 0% N/A |
|-------------------------------+----------------------+----------------------+
| Compute Processes: AIP Memory |
| AIP PID Type Process name Usage |
|=============================================================================|We can see that we have 8 HPU devices available for our training routines and that we are running SynapseAI with version 1.10.0
Wielding the Habana PyTorch Docker
Next, we need to install PyTorch bindings to run our training routines. You can do this on a bare metal install, but it is advisable to develop within the official provided Habana docker images.
In our case, we launch with SynapseAI 1.10.0 and develop on top of this docker image:
sudo docker run -it --runtime=habana -e HABANA_VISIBLE_DEVICES=all -e OMPI_MCA_btl_vader_single_copy_mechanism=none --cap-add=sys_nice --net=host --ipc=host vault.habana.ai/gaudi-docker/1.10.0/ubuntu20.04/habanalabs/pytorch-installer-2.0.1:latestConfiguring Multi-HPU ViT Training
Next up, we will prepare our machine to run ViT on multi-HPU, primarliy following this guide from the Habana team.
Installing Dependencies
git clone -b 1.10.0 https://github.com/HabanaAI/Model-References /root/Model-References
export PYTHONPATH=$PYTHONPATH:/root/Model-References
cd /root/Model-References/PyTorch/computer_vision/classification/ViT/
pip install -r requirements.txt
Downloading ViT Model Weights
Then we download the pretrained model weights - you have a section between ImageNet pretrained ViT-B_16, ViT-B_32, ViT-L_16, ViT-L_32, ViT-H_14 or with an additional ImageNet2012 finetuning step ViT-B_16-224, ViT-L_16-224
We'll stick with the vanilla ViT ImageNet pretrained weights. This model has 86 million parameters.
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
Downloading Imagenette Dataset
Let's check our configuration by running training on a Imagenette, a slim version of ImageNet from fastai - https://github.com/fastai/imagenette. wget https://s3.amazonaws.com/fast-ai-imageclas/imagenette2-160.tgz
tar -xzf imagenette2-160.tgz
Running Multi-HPU Training
We can kick off training using DDP with the Habana mpi runner.
mpirun -n 8 --bind-to core --map-by socket:PE=6 --rank-by core --report-bindings --allow-run-as-root python -u train.py --name imagenet1k_TF --dataset imagenet1K --data_path ./imagenette2-160 --model_type ViT-B_16 --pretrained_dir ./ViT-B_16.npz --num_steps 20000 --eval_every 1000 --train_batch_size 256 --gradient_accumulation_steps 2 --img_size 160 --learning_rate 0.06 --hmp --hmp-opt-level O1And then we will see our training kick off on all 8 Gaudi2 HPUs
Training (X / X Steps) (loss=X.X): 10%|| 1/10 [00:05<00:46, 5.19s/it]07/27/2023 20:50:12 - INFO - torch.nn.parallel.distributed - Reducer buckets have been rebuilt in this iteration.
Training (5 / 20000 Steps) (loss=6.90622 images/sec=1118.00737): 100%|| 10/10 [00:14<00:00, 1.43s/it]
Training (10 / 20000 Steps) (loss=6.89151 images/sec=13879.58214): 100%|| 10/10 [00:01<00:00, 7.16it/s]
Training (15 / 20000 Steps) (loss=6.85838 images/sec=13907.87475): 100%|| 10/10 [00:01<00:00, 7.00it/s]
Training (20 / 20000 Steps) (loss=6.79324 images/sec=14051.43058): 100%|| 10/10 [00:01<00:00, 7.19it/s]
Training (25 / 20000 Steps) (loss=6.72665 images/sec=14080.26730): 100%|| 10/10 [00:01<00:00, 7.06it/s]
Training (30 / 20000 Steps) (loss=6.60213 images/sec=14230.46335): 100%|| 10/10 [00:01<00:00, 7.13it/s]
Training (35 / 20000 Steps) (loss=6.48191 images/sec=13777.40199): 100%|| 10/10 [00:01<00:00, 6.92it/s]
Training (40 / 20000 Steps) (loss=6.32684 images/sec=13870.75169): 100%|| 10/10 [00:01<00:00, 6.97it/s]
Training (45 / 20000 Steps) (loss=6.07043 images/sec=13793.37494): 100%|| 10/10 [00:01<00:00, 7.18it/s]
Training (50 / 20000 Steps) (loss=5.89593 images/sec=14217.93259): 100%|| 10/10 [00:01<00:00, 7.21it/s]
Training (55 / 20000 Steps) (loss=5.55210 images/sec=14236.12356): 100%|| 10/10 [00:01<00:00, 7.07it/s]
Training (60 / 20000 Steps) (loss=5.05965 images/sec=14579.84536): 100%|| 10/10 [00:01<00:00, 7.25it/s]
Training (65 / 20000 Steps) (loss=4.57578 images/sec=14275.27831): 100%|| 10/10 [00:01<00:00, 7.21it/s]
Training (70 / 20000 Steps) (loss=3.98769 images/sec=14638.33260): 100%|| 10/10 [00:01<00:00, 7.20it/s]
Training (75 / 20000 Steps) (loss=3.52915 images/sec=13738.92735): 100%|| 10/10 [00:01<00:00, 7.03it/s]
Training (80 / 20000 Steps) (loss=2.88970 images/sec=14178.57647): 100%|| 10/10 [00:01<00:00, 6.86it/s]
Training (85 / 20000 Steps) (loss=2.02656 images/sec=13549.81859): 100%|| 10/10 [00:01<00:00, 6.49it/s]
Training (90 / 20000 Steps) (loss=1.04811 images/sec=14174.24820): 100%|| 10/10 [00:01<00:00, 7.12it/s]We can also double check hl-smi to make sure all of our HPUs are being utilized during training.
+-----------------------------------------------------------------------------+
| HL-SMI Version: hl-1.10.0-fw-43.2.0.0 |
| Driver Version: 1.10.0-416d95e |
|-------------------------------+----------------------+----------------------+
| AIP Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | AIP-Util Compute M. |
|===============================+======================+======================|
| 0 HL-225 N/A | 0000:19:00.0 N/A | 0 |
| N/A 40C N/A 310W / 600W | 98304MiB / 98304MiB | 34% N/A |
|-------------------------------+----------------------+----------------------+
| 1 HL-225 N/A | 0000:b3:00.0 N/A | 0 |
| N/A 39C N/A 266W / 600W | 98304MiB / 98304MiB | 30% N/A |
|-------------------------------+----------------------+----------------------+
| 2 HL-225 N/A | 0000:b4:00.0 N/A | 0 |
| N/A 43C N/A 307W / 600W | 98304MiB / 98304MiB | 58% N/A |
|-------------------------------+----------------------+----------------------+
| 3 HL-225 N/A | 0000:cc:00.0 N/A | 0 |
| N/A 44C N/A 362W / 600W | 98304MiB / 98304MiB | 66% N/A |
|-------------------------------+----------------------+----------------------+
| 4 HL-225 N/A | 0000:cd:00.0 N/A | 0 |
| N/A 40C N/A 234W / 600W | 98304MiB / 98304MiB | 43% N/A |
|-------------------------------+----------------------+----------------------+
| 5 HL-225 N/A | 0000:1a:00.0 N/A | 0 |
| N/A 45C N/A 352W / 600W | 98304MiB / 98304MiB | 65% N/A |
|-------------------------------+----------------------+----------------------+
| 6 HL-225 N/A | 0000:43:00.0 N/A | 0 |
| N/A 45C N/A 225W / 600W | 98304MiB / 98304MiB | 44% N/A |
|-------------------------------+----------------------+----------------------+
| 7 HL-225 N/A | 0000:44:00.0 N/A | 0 |
| N/A 42C N/A 142W / 600W | 98304MiB / 98304MiB | 9% N/A |
|-------------------------------+----------------------+----------------------+Running Training on Roboflow Classification Datasets
You can scale up your own ViT classification training routines on the Gaudi2 with Roboflow datasets. For this tutorial we select a covid XRay classification dataset from Roboflow Universe.
You can download this with Roboflow's PIP package
!pip install roboflow
import roboflow
roboflow.login()
from roboflow import Roboflow
rf = Roboflow()
project = rf.workspace("new-workspace-onq0e").project("covid-x-ray-images")
dataset = project.version(1).download("folder")
Unfortunately this dataset is missing a val set, so we will use the test set for validation mv covid-xrays/test/ covid-xrays/val
Then we kick off training as before pointed at our custom dataset:
mpirun -n 8 --bind-to core --map-by socket:PE=6 --rank-by core --report-bindings --allow-run-as-root python -u train.py --name imagenet1k_TF --dataset imagenet1K --data_path ./covid-xrays/ --model_type ViT-B_16 --pretrained_dir ./ViT-B_16.npz --num_steps 5000 --eval_every 500 --train_batch_size 256 --gradient_accumulation_steps 2 --img_size 224 --learning_rate 0.06 --hmp --hmp-opt-level O1
Training (X / X Steps) (loss=X.X): 6%|| 1/17 [00:07<01:52, 7.04s/it]07/27/2023 21:29:32 - INFO - torch.nn.parallel.distributed - Reducer buckets have been rebuilt in this iteration.
Training (8 / 5000 Steps) (loss=6.88516 images/sec=10638.61213): 100%|| 17/17 [00:19<00:00, 1.12s/it]
Training (16 / 5000 Steps) (loss=6.73138 images/sec=10535.19517): 100%|| 17/17 [00:02<00:00, 6.65it/s]
Training (24 / 5000 Steps) (loss=6.39110 images/sec=10512.15588): 100%|| 17/17 [00:02<00:00, 6.72it/s]
Training (32 / 5000 Steps) (loss=5.82177 images/sec=10613.08594): 100%|| 17/17 [00:02<00:00, 6.54it/s]
Training (40 / 5000 Steps) (loss=4.92819 images/sec=10568.19502): 100%|| 17/17 [00:02<00:00, 6.63it/s]
Training (48 / 5000 Steps) (loss=3.76735 images/sec=10574.59590): 100%|| 17/17 [00:02<00:00, 6.80it/s]
Training (56 / 5000 Steps) (loss=2.82828 images/sec=10506.29293): 100%|| 17/17 [00:02<00:00, 6.52it/s]
Training (64 / 5000 Steps) (loss=2.28397 images/sec=10516.10677): 100%|| 17/17 [00:02<00:00, 6.53it/s]
Training (72 / 5000 Steps) (loss=1.93765 images/sec=10562.13953): 100%|| 17/17 [00:02<00:00, 6.55it/s]
Training (80 / 5000 Steps) (loss=1.56841 images/sec=10595.40015): 100%|| 17/17 [00:02<00:00, 6.65it/s]
Training (88 / 5000 Steps) (loss=1.37217 images/sec=10579.67528): 100%|| 17/17 [00:02<00:00, 6.79it/s]
Training (96 / 5000 Steps) (loss=1.12434 images/sec=10595.25639): 100%|| 17/17 [00:02<00:00, 6.60it/s]
Training (104 / 5000 Steps) (loss=0.95305 images/sec=10589.06543): 100%|| 17/17 [00:02<00:00, 6.51it/s]
Training (112 / 5000 Steps) (loss=0.86925 images/sec=10579.21924): 100%|| 17/17 [00:02<00:00, 6.69it/s]
Training (120 / 5000 Steps) (loss=0.79212 images/sec=10524.70088): 100%|| 17/17 [00:02<00:00, 6.53it/s]Conclusion
In this blog, we scaled up the training of a large ViT classification model on multi-HPU using Gaudi2 devices on the Intel developer cloud. We showed how we can adapt the ViT training routines to custom image classification datasets that are labeled in Roboflow.
For transformer training, Intel's Gaudi2's offer a competitive hardware option for running large training workloads.
Happy training!