
The world population is expected to reach 9.7 billion by 2050. That’s a lot of mouths to feed.
Technology is powering the next generation of yield increases. Computer vision is especially critical to greener, more efficient production. For example, Blue River’s (John Deere) “See & Spray” enables machinery to do weed detection in real-time, deploying 90 percent less herbicide while more effectively targeting problematic weeds.

But computer vision in agriculture is just beginning — and more open source data is key to increasing its rate of adoption. We're already starting to see self-driving combines, automated phenotyping, and autonomous tractors powering a revolution in precision ag.
Introducing the PlantDoc Dataset
In fall 2019, researchers at Indian Institute of Technology released PlantDoc, a dataset of 2,598 images across 13 plant species and 27 classes (17 disease; 10 healthy) for image classification and object detection. The researchers note the dataset’s creation took over 300 human hours of collecting and annotating. Unlike similar datasets like CropDeep and DeepWeeds, this dataset is available for the public to download for deep learning researchers to use for free!

One of the paper’s authors, Pratik Kayal, shared the object detection dataset available on GitHub.
Adding PlantDoc to Roboflow Public Datasets
At Roboflow, we’re committed to advancing computer vision work in all industries, including agriculture. We’re hosting the dataset on Roboflow Public Datasets, available in any annotation format you may need: VOC XML, COCO JSON, CreateML JSON, and even TFRecords. The dataset follows the same train/test split Pratik Kayal’s GitHub release did for easy reproducibility of your machine learning experiments.
When we added the dataset to Roboflow and took advantage of automated annotation checking, we identified opportunities for improvement, so the dataset varies slightly from the original in a few ways.
Firstly, over 28 annotations were corrected. In some cases, the bounding boxes were slightly out of frame and, thus, cropped to be in-line with the edge of the image. Yet others were accidentally bounding zero pixels and dropped altogether. 25 of these were in the training set, and three were in the test set. When humans are tasked with over 300 hours of labelling to create 8,851 bounding boxes, mistakes happen! Roboflow identifies and corrects these issues automatically for any dataset.
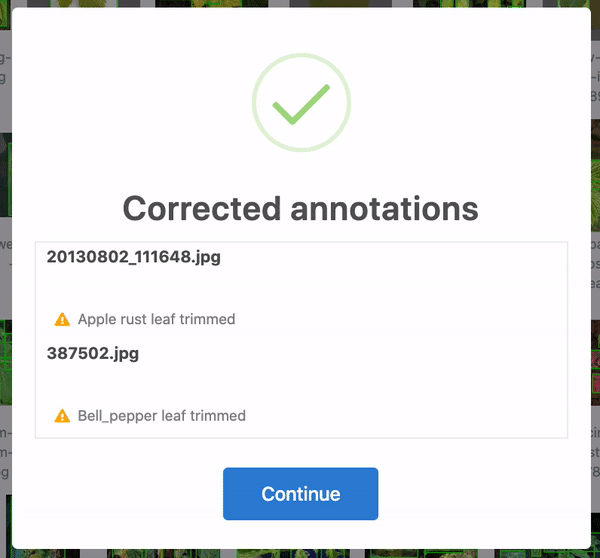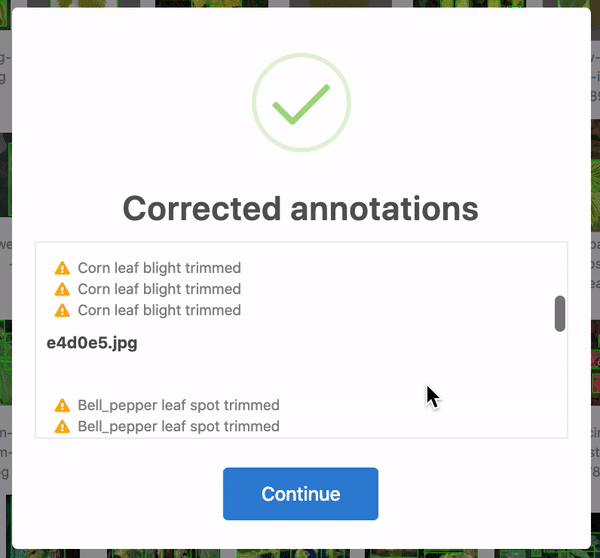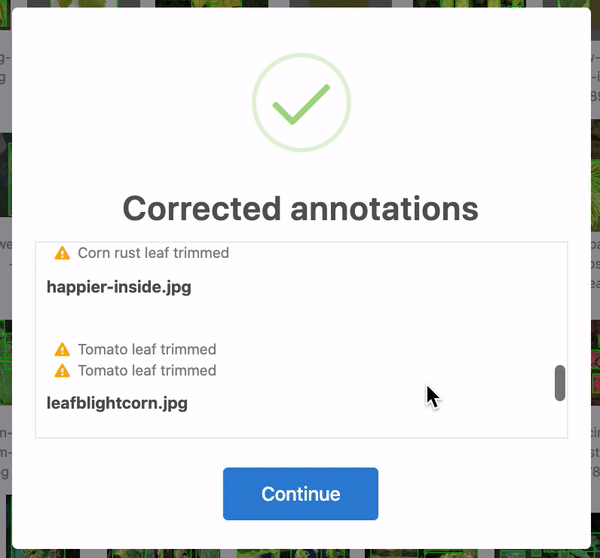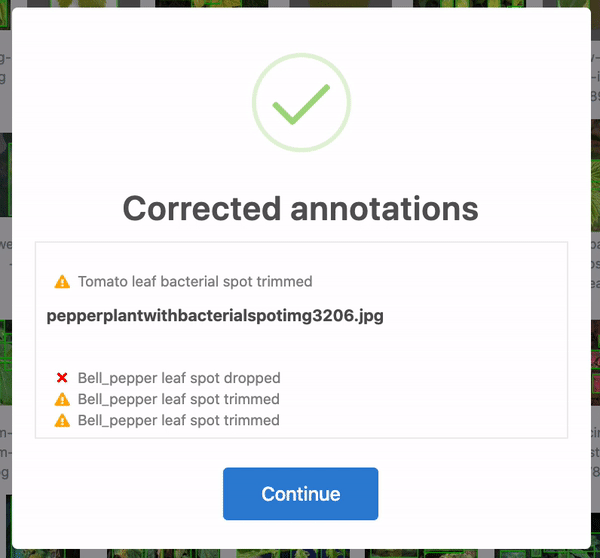
Secondly, five images did not contain any labels. In the training set, this included images originally titled Tdisease_1.jpg, ac-0018.pdf-2_2.jpg, and Tomato%20physiologic%20leaf%20roll1F.JPG.jpg. In the test set, this included images originally titled Summersquashpowderymildew.jpg and stock-photo-cultivar-marrow-leaf-strongly-affected-with-a-powdery-mildew-in-the-summer-garden-707948062.jpg. We are not plant biologists as the original authors are. However, based on context and research from The Ohio State University [1] [2], we were able to infer how the original images should have been labeled and corrected them by hand.
Use Cases for PlantDoc
As the researchers from IIT stated in their paper, “plant diseases alone cost the global economy around US$220 billion annually.” Training models to recognize plant diseases earlier dramatically increases yield potential.
The dataset also serves as a useful open dataset for benchmarks. The researchers trained both object detection models like YOLOv4, MobileNet and Faster-RCNN and image classification models like VGG16, InceptionV3, and EfficientNet.
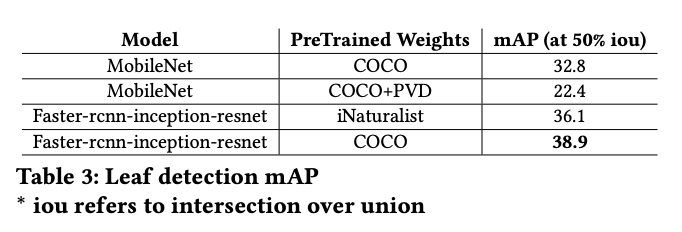
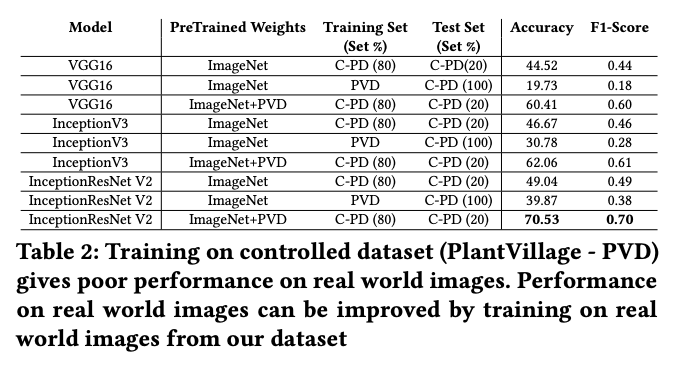
The dataset is useful for advancing general agriculture computer vision tasks, whether that be health crop classification, plant disease classification, or plant disease object detection.
With computer vision poised to continue to transform agriculture as a sector, we’re excited to see how making the PlantDoc dataset more accessible advances research interests.