
The YOLO family of object detection models grows ever stronger with the introduction of YOLOv5. In this post, we will walk through how you can train YOLOv5 to recognize your custom objects for your use case.
We use a public blood cell detection dataset, which you can export yourself. You can also use this tutorial on your own custom data.
To train our YOLOv5 object detection model, we will:
- Install YOLOv5 dependencies
- Download Custom YOLOv5 Object Detection Data
- Define YOLOv5 Model Configuration and Architecture
- Train a custom YOLOv5 Detector
- Evaluate YOLOv5 performance
- Visualize YOLOv5 training data
- Run YOLOv5 Inference on test images
- Export Saved YOLOv5 Weights for Future Inference
YOLOv5 Custom Dataset Training
On to training... We recommend following along concurrently in this YOLOv5 Colab Notebook.
Check out our Autodistill guide for more information, and our Autodistill YOLOv5 documentation.
Installing the YOLOv5 Environment
To start off we first clone the YOLOv5 repository and install dependencies. This will set up our programming environment to be ready to running object detection training and inference commands.
!git clone https://github.com/ultralytics/yolov5 # clone repo
!pip install -U -r yolov5/requirements.txt # install dependencies
%cd /content/yolov5
Then, we can take a look at our training environment provided to us for free from Google Colab.
import torch
from IPython.display import Image # for displaying images
from utils.google_utils import gdrive_download # for downloading models/datasets
print('torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))It is likely that you will receive a Tesla P100 GPU from Google Colab. Here is what we received:
torch 1.5.0+cu101 _CudaDeviceProperties(name='Tesla P100-PCIE-16GB', major=6, minor=0, total_memory=16280MB, multi_processor_count=56)The GPU will allow us to accelerate training time. Colab comes preinstalled with torch and cuda. If you are attempting this tutorial on local, there may be additional steps to take to set up YOLOv5.
Download Custom YOLOv5 Object Detection Data
In this tutorial we will download object detection data in YOLOv5 format from Roboflow. In the tutorial, we train YOLOv5 to detect cells in the blood stream with a public blood cell detection dataset. You can follow along with the public blood cell dataset or upload your own dataset.
Using Your Own Data
To export your own data for this tutorial, sign up for Roboflow and make a public workspace, or make a new public workspace in your existing account. If your data is private, you can upgrade to a paid plan for export to use external training routines like this one or experiment with using Roboflow's internal training solution.
Label and Annotate Data with Roboflow for free
Use Roboflow to manage datasets, label data, and convert to 26+ formats for using different models. Roboflow is free up to 10,000 images, cloud-based, and easy for teams.
To get started, label any unlabeled images. For free open source labeling tools, we recommend Roboflow Annotate or the following guides on getting started with LabelImg or getting started with CVAT annotation tools.
Try labeling ~50 images to proceed in this tutorial. You will want to label more images to improve your model's performance later.
Labeling images with Roboflow Annotate
Once you have labeled data, to move your data into Roboflow, you can drag your dataset into the app in any format: (VOC XML, COCO JSON, TensorFlow Object Detection CSV, etc).
Once uploaded you can choose preprocessing and augmentation steps:
Then, click Generate and Download and you will be able to choose YOLOv5 PyTorch format.
When prompted, select "Show Code Snippet." This will output a download curl script so you can easily port your data into Colab in the proper format.
curl -L "https://public.roboflow.ai/ds/YOUR-LINK-HERE" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip
****Note you can now also download your data with the Roboflow PIP Package
#from roboflow import Roboflow
#rf = Roboflow(api_key="YOUR API KEY HERE")
#project = rf.workspace().project("YOUR PROJECT")
#dataset = project.version("YOUR VERSION").download("yolov5")Downloading in Colab...
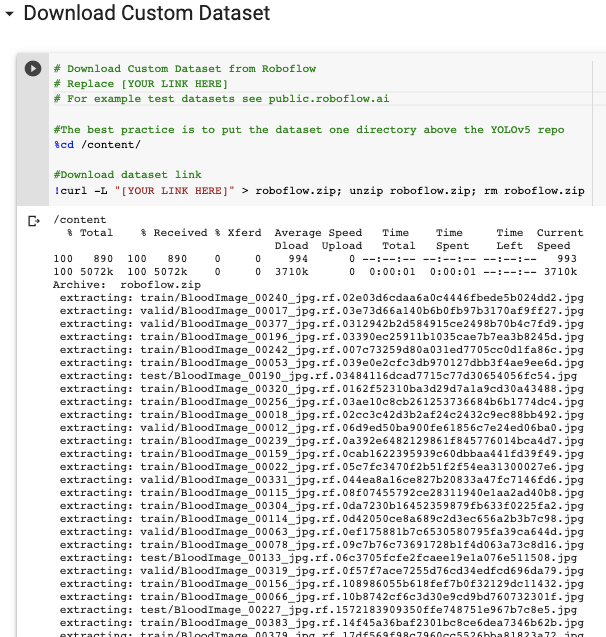
The export creates a YOLOv5 .yaml file called data.yaml specifying the location of a YOLOv5 images folder, a YOLOv5 labels folder, and information on our custom classes.
Define YOLOv5 Model Configuration and Architecture
Next we write a model configuration file for our custom object detector. For this tutorial, we chose the smallest, fastest base model of YOLOv5. You have the option to pick from other YOLOv5 models including:
- YOLOv5s
- YOLOv5m
- YOLOv5l
- YOLOv5x
You can also edit the structure of the network in this step, though rarely will you need to do this. Here is the YOLOv5 model configuration file, which we term custom_yolov5s.yaml:
nc: 3
depth_multiple: 0.33
width_multiple: 0.50
anchors:
- [10,13, 16,30, 33,23]
- [30,61, 62,45, 59,119]
- [116,90, 156,198, 373,326]
backbone:
[[-1, 1, Focus, [64, 3]],
[-1, 1, Conv, [128, 3, 2]],
[-1, 3, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]],
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]],
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]],
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 6, BottleneckCSP, [1024]],
]
head:
[[-1, 3, BottleneckCSP, [1024, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]],
[-2, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]],
[-2, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]],
[[], 1, Detect, [nc, anchors]],
]Training Custom YOLOv5 Detector
With our data.yaml and custom_yolov5s.yaml files ready, we can get started with training.
To kick off training we running the training command with the following options:
- img: define input image size
- batch: determine batch size
- epochs: define the number of training epochs.
- data: set the path to our yaml file
- cfg: specify our model configuration
- weights: specify a custom path to weights. (Note: you can download weights from the Ultralytics Google Drive folder)
- name: result names
- nosave: only save the final checkpoint
- cache: cache images for faster training
And run the training command:
Training the custom YOLOv5 Detector
During training, you want to be watching the mAP@0.5 to see how your detector is performing - see this post on breaking down mAP.
Evaluate Custom YOLOv5 Detector Performance
Now that we have completed training, we can evaluate how well the training procedure performed by looking at the validation metrics. The training script will drop tensorboard logs in runs. We visualize those here:
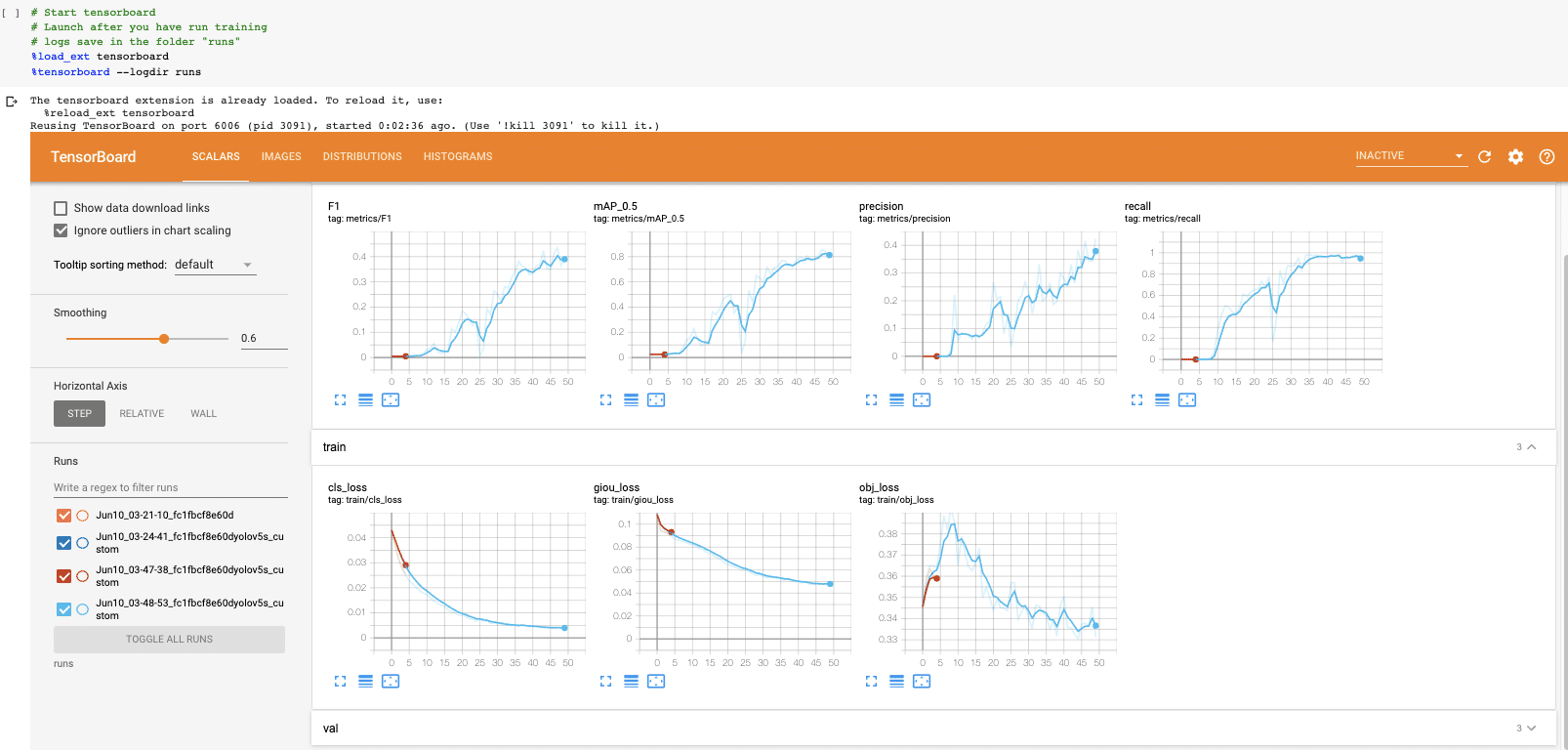
And if you can't visualize Tensorboard for whatever reason the results can also be plotted with utils.plot_results and saving a result.png.
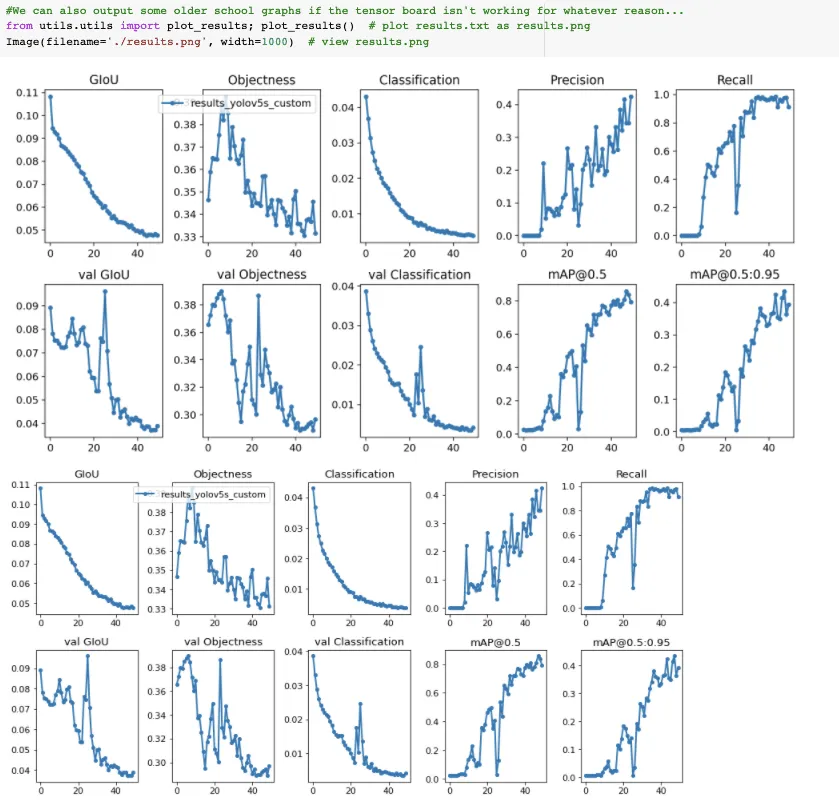
We stopped training a little early here. You want to take the trained model weights at the point where the validation mAP reaches its highest.
Visualize YOLOv5 training data
During training, the YOLOv5 training pipeline creates batches of training data with augmentations. We can visualize the training data ground truth as well as the augmented training data.
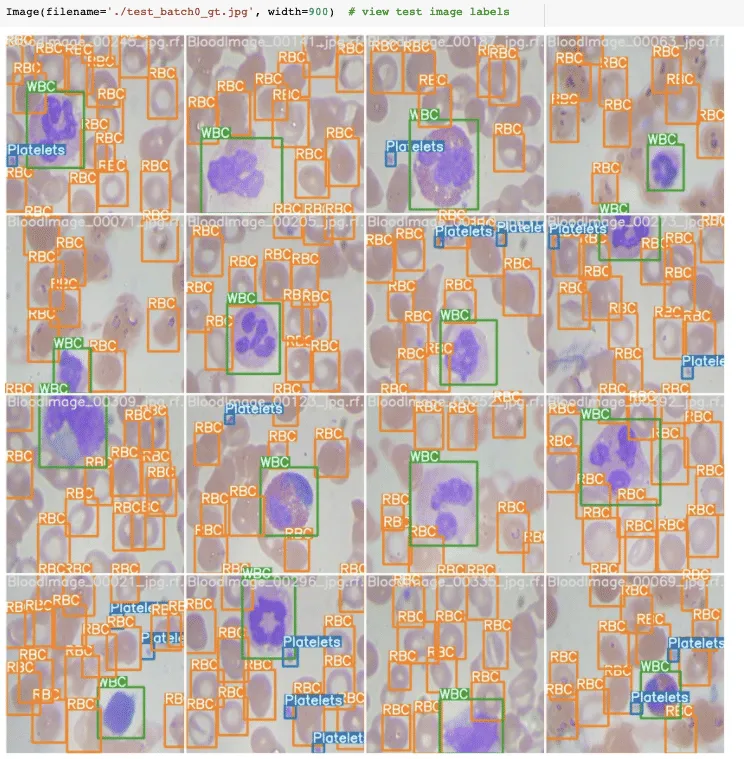
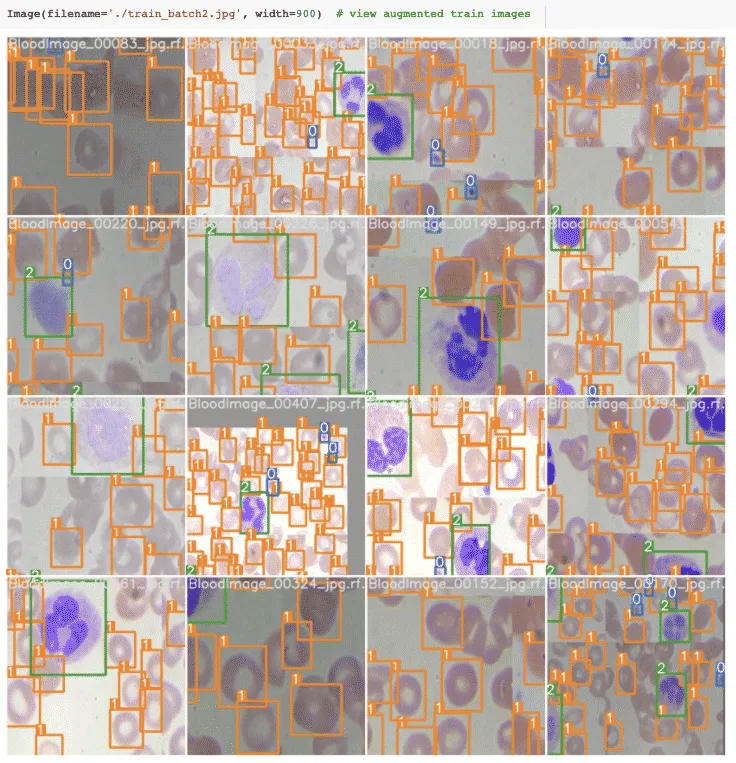
Run YOLOv5 Inference on Test Images
Now we take our trained model and make inference on test images. After training has completed model weights will save in weights/.
For inference we invoke those weights along with a conf specifying model confidence (higher confidence required makes less predictions), and a inference source. source can accept a directory of images, individual images, video files, and also a device's webcam port. For source, I have moved our test/*jpg to test_infer/.
!python detect.py --weights weights/last_yolov5s_custom.pt --img 416 --conf 0.4 --source ../test_inferThe inference time is extremely fast. On our Tesla P100, the YOLOv5 is reaching 142 FPS.
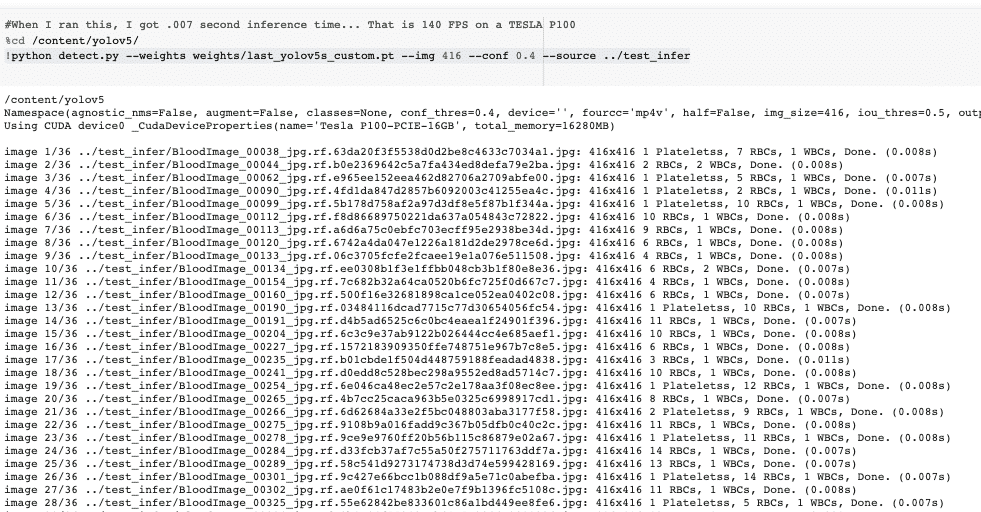
Finally, we visualize our detectors inferences on test images.
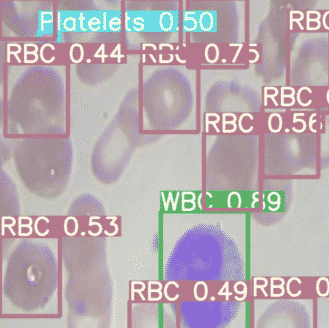
Export Saved YOLOv5 Weights for Future Inference
Now that our custom YOLOv5 object detector has been verified, we might want to take the weights out of Colab for use on a live computer vision task. To do so we import a Google Drive module and send them out.
from google.colab import drive
drive.mount('/content/gdrive')
%cp /content/yolov5/weights/last_yolov5s_custom.pt /content/gdrive/My\ DriveDeploy to Roboflow
Once you have finished training your YOLOv5 model, you’ll have a set of trained weights ready for use with a hosted API endpoint. These weights will be in the “/runs/detect/train/weights/best.pt” folder of your project. You can upload your model weights to Roboflow Deploy with the deploy() function in the Roboflow pip package to use your trained weights.
To upload model weights, first create a new project on Roboflow, upload your dataset, and create a project version. Check out our complete guide on how to create and set up a project in Roboflow. Then, write a Python script with the following code:
import roboflow
roboflow.login()
rf = roboflow.Roboflow()
project = rf.workspace().project(PROJECT_ID)
project.version(DATASET_VERSION).deploy(model_type=”yolov5”, model_path=f”{HOME}/runs/detect/train/”)Replace PROJECT_ID with the ID of your project and DATASET_VERSION with the version number associated with your project. Learn how to find your project ID and dataset version number.
Shortly after running the above code, your model will be available for use in the Deploy page on your Roboflow project dashboard.
Deploy Your Model to the Edge
In addition to using the Roboflow hosted API for deployment, you can use Roboflow Inference, an open source inference solution that has powered millions of API calls in production environments. Inference works with CPU and GPU, giving you immediate access to a range of devices, from the NVIDIA Jetson to TRT-compatible devices to ARM CPU devices.

With Roboflow Inference, you can self-host and deploy your model on-device.
You can deploy applications using the Inference Docker containers or the pip package. In this guide, we are going to use the Inference Docker deployment solution. First, install Docker on your device. Then, review the Inference documentation to find the Docker container for your device.
For this guide, we'll use the GPU Docker container:
docker pull roboflow/roboflow-inference-server-gpuThis command will download the Docker container and start the inference server. This server is available at http://localhost:9001. To run inference, we can use the following Python code:
import requests
workspace_id = ""
model_id = ""
image_url = ""
confidence = 0.75
api_key = ""
infer_payload = {
"image": {
"type": "url",
"value": image_url,
},
"confidence": confidence,
"iou_threshold": iou_thresh,
"api_key": api_key,
}
res = requests.post(
f"http://localhost:9001/{workspace_id}/{model_id}",
json=infer_object_detection_payload,
)
predictions = res.json()Above, set your Roboflow workspace ID, model ID, and API key.
Also, set the URL of an image on which you want to run inference. This can be a local file.
To use your YOLOv5 model commercially with Inference, you will need a Roboflow Enterprise license, through which you gain a pass-through license for using YOLOv5. An enterprise license also grants you access to features like advanced device management, multi-model containers, auto-batch inference, and more.
To learn more about deploying commercial applications with Roboflow Inference, contact the Roboflow sales team.
Conclusion to Training YOLOv5 on Custom Data
YOLO v5 is lightweight and extremely easy to use because it trains quickly, inferences fast, and performs well.
We hoped you enjoyed training your custom YOLO v5 detector.
YOLOv5: What's New?
Only two months ago, we were very excited about the introduction of EfficientDet by Google Brain and wrote some blog posts breaking down EfficientDet. We thought this model might eclipse the YOLO family for prominence in the realtime object detection algorithm space - we were wrong.
Within three weeks, YOLOv4 was released in the Darknet framework and we wrote some more on breaking down the research in YOLOv4.
Then a few hours before the writing of this, YOLOv5 has been released and we have found it to be extremely sleek. YOLO v5 is written in the Ultralytics PyTorch framework, which is very intuitive to use and inferences very fast.
In fact, we and many others would often translate YOLOv3 and YOLOv4 Darknet weights to the Ultralytics PyTorch weights in order to inference faster with a lighter library.
Our team analyzed YOLOv5 vs YOLOv4 for you to see which version is best.
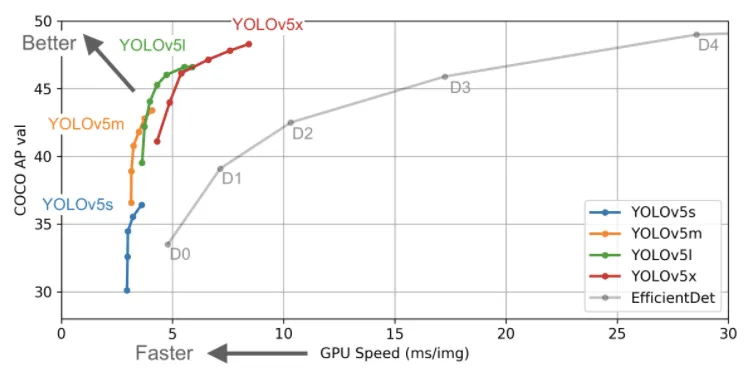
YOLOv4 is notably left out of the evaluation on the YOLO v5 repository. That said, YOLO v5 is certainly easier to use and it is very performant on custom data based on our initial runs.