Impatient? Jump to our VGG-16 Colab notebook.
Image classification models discern what a given image contains based on the entirety of an image's content. And while they're consistently getting better, the ease of loading your own dataset seems to stay the same. That's where Roboflow comes in.
About VGG-16
VGG-16 paper was released by researchers at the University of Oxford in 2015. (Hence VGG: that's the Visual Geometry Group as Oxford.) The model achieves an impressive 92.7 percent top-5 test accuracy in ImageNet, making it a continued top choice architecture for prioritizing accurate performance.
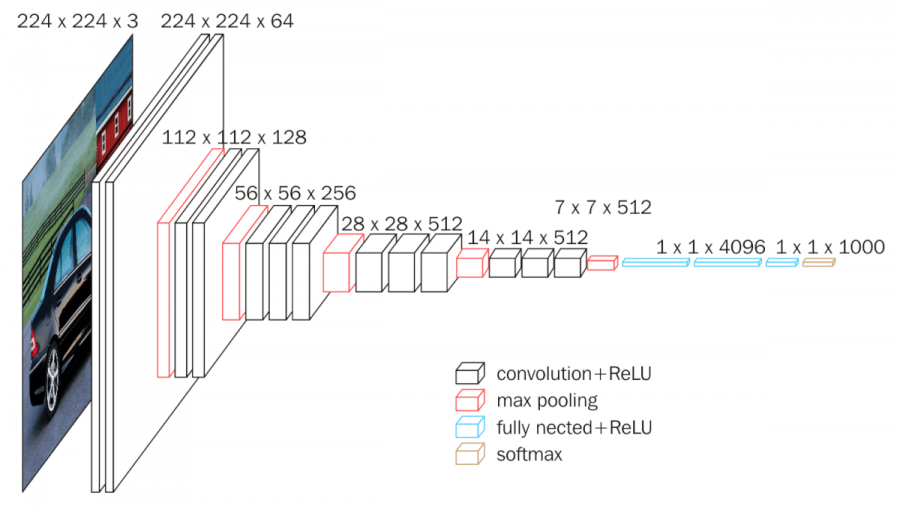
The model's key insight demonstrated the importance of using a high number of very small convolutional filters, which allows it to learn on more complex pixel relational data, or the detail in images.
Our Implementation in Google Colab
We'll be using a VGG-16 Colab notebook and Roboflow to prepare our data. Our Vgg-16 implementation is in TensorFlow, based on the work from the TensorFlow-Slim team's work.
At this point, open up the VGG-16 Tensorflow Google Colab Notebook to proceed!
Setting Up Our Notebook
In the first portion of our notebook, we download required libraries and packages to ensure our environment is set up for success. This includes the TensorFlow Research Team's implementation of TF-Slim, cloning TensorFlow models, and standard libraries like matplotlib for plotting. Notably, we'll also use Colab Notebook magic commands (yes, that's what they are called) to run Tensorflow 1.x for compatibility with TF-Slim.
Getting Our Data From Roboflow
Next, we'll download our data from a code snippet from Roboflow. Specifically, we'll create a classification dataset, apply preprocessing steps (like resizing to the aspect ratio we prefer), and adding any augmentation to increase the training dataset size while reducing overfitting.
VGG-16 expects an input size of 224x224, so we should at least resize our images to be a square. Whether you preserve the aspect ratio (like using black padding, reflecting pixels, or a center crop) depends on your problem context. Remember to consider how to resize images for computer vision.
Augmentation increases the number of images in our dataset. Doing augmentation with classification data is especially powerful: we can modify the brightness of our scene, contrast, add noise, rotation, and more directly in Roboflow with a single click. Moreover, we are able to determine the number of augmentations we want to apply.
For the example in our notebook, we're making use of the flowers classification dataset, publicly available at https://public.roboflow.ai. Our version of the flowers dataset contains only two flower varieties: daisies and dandelions.
Preparing Our Input Pipeline
Once our data is loaded into the notebook, we'll adapt and create TFRecord files specific to how this TF-Slim implementation expects. Fortunately, scripts are largely written for us. Pay special attention to setting the image validation set size and training size when considering your own problem.
Loading Pre-Trained Weights
In our notebook, before training to our specific problem (flowers), you'll note we first load a generic model trained on ImageNet. This means we've loaded a VGG-16 model with ImageNet weights – meaning our network can, out-of-the-box, recognize every one of ImageNet's 200 images. (If your dataset happens to have classes already contained within ImageNet, theoretically, you could stop here and have a trained model!)
In our notebook, note we output the success of ImageNet in recognizing a school bus from Wikimedia.

Adapting VGG-16 to Our Dataset
From here, we load our specific dataset and its classes, and have our training commence from learning the prior weights of ImageNet. Notably, we will have to update our network's final layers to be aware that we have fewer classes now than ImageNet's 2000!
The training for this step can vary in time. Critically, Colab provides free GPU compute, but the kernel will not last longer than 12 hours and is reported to die after 45 minutes of inactivity – so no watching (too much) Netflix while waiting for this model to train.
Conducting Inference
Lastly, we use our model's new weights to conduct inference on images it has not yet seen before in the test set.
![Two example images 1: Ground Truth: [sunflowers], Prediction [sunflowers], 2: Ground Truth: [daisy], Prediction [sunflowers]](https://blog.roboflow.com/content/images/2020/06/vgg-flower-output.png)
All-in-all, the process is fairly straight forward: (1) get your data (2) set up a pre-trained model (3) adapt that model to your problem.
Happy building!