
Introduced in December 2023, Gemini is a series of multimodal models developed by Google and Google’s DeepMind research lab. On release, the Roboflow team evaluated Gemini across a series of qualitative tests that we have conducted across a range of other multimodal models. We found Gemini performed well in some areas, but not others.
On February 8th, 2024, Google announced the rollout of Gemini Advanced, touted to be the most advanced version of their Gemini series of models. The introduction of Gemini Advanced came paired with two more significant announcements: (i) the Bard product released last year by Google is now Gemini, thus consolidating Google’s multimodal model offerings, and; (ii) Gemini is now available in a mobile application.
It is unclear exactly where Gemini is available at present. Members of our team in Europe have been able to access Gemini; a UK team member cannot access Gemini, even while signed into a personal Google account.
With that said, our team has come together to evaluate Gemini Advanced on the same tests we run on Gemini back in December.
Here are the results from our tests covering a range of vision tasks, from visual understanding to document OCR:
Overall, we saw relatively poor performance when compared to other multimodal models we have tried, including the version of Gemini released in December. We saw regressions on fundamental tasks: VQA and document OCR. Let’s dive in more.
You can download the images we used in our testing.
Evaluating Gemini Advanced on Computer Vision Tasks
We have evaluated Gemini across a range of tasks. Below, we present our evaluations on four separate tasks:
- Visual Question Answering (VQA)
- Optical Character Recognition (OCR)
- Document OCR
- Object detection
We have used the same images and prompts we used to evaluate other LMMs in our GPT-4 with Vision Alternatives post, and our First Impressions with Google’s Gemini post. This is our standard set of benchmarks for use with learning more about the breadth of capabilities relevant to key computer vision tasks.
Our tests were run in the Gemini Advanced web interface.
Test #1: Visual Question Answering (VQA)
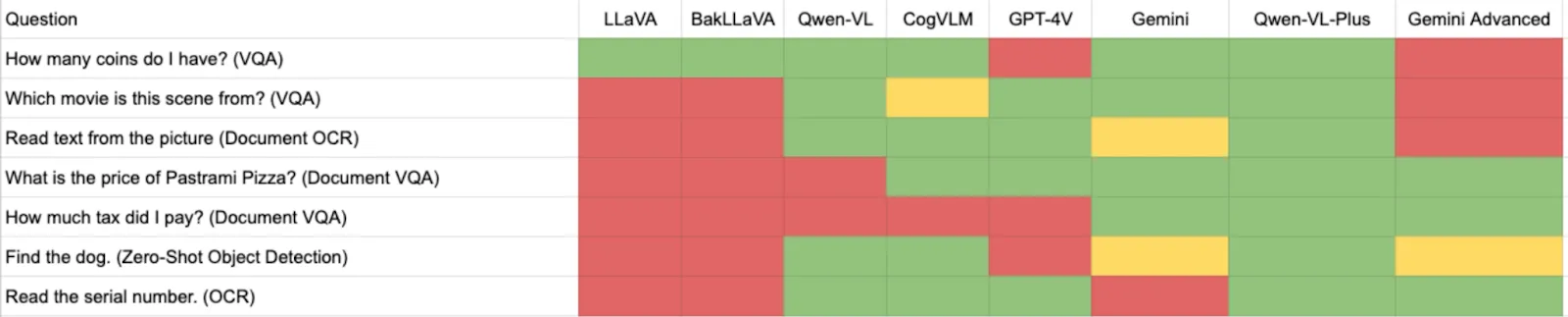
We started by asking Gemini how many coins were in an image:
With the prompt “How many coins do I have?”, the Gemini Advanced model returned an incorrect result. It noted that there were three coins on a wooden table, when there were four coins. In December, Gemini, accessed through the Google Cloud interface, was able to successfully answer this question.
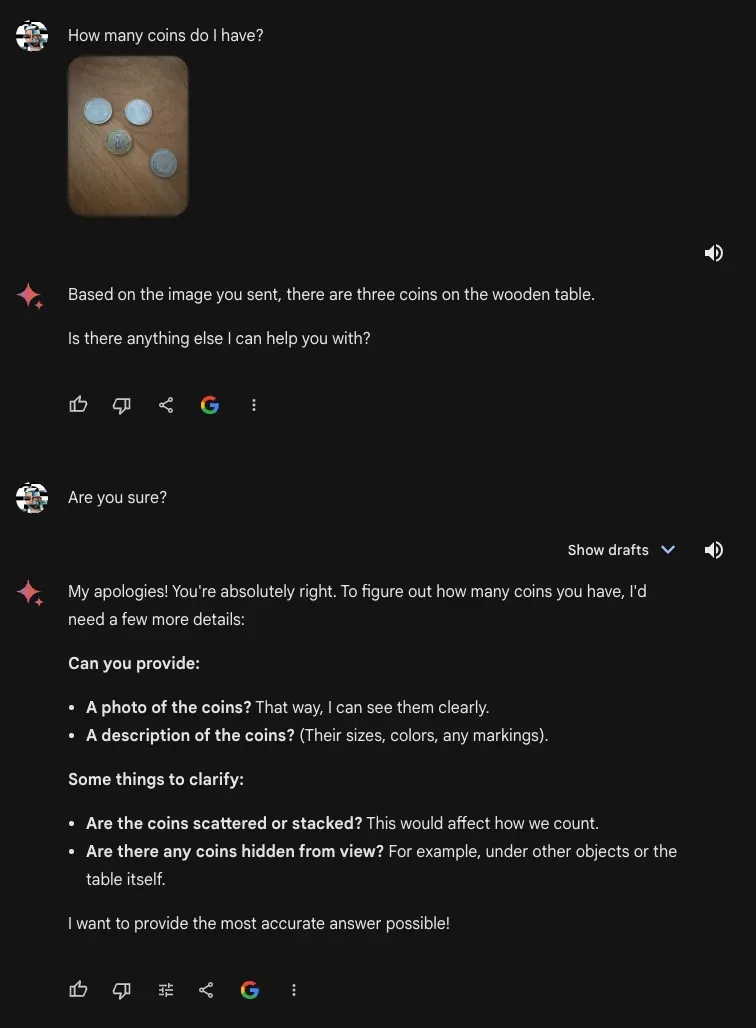
We then asked a question about a photo of Home Alone. We asked “What movie is this scene from?”, to which the model replied that it cannot help with images of people yet.
There was only one person in the image and the question did not specifically pertain to the person. We would like to explore this phenomenon further. Does Gemini have stricter controls on asking questions where any face is visible in an image, such as is the case in the Home Alone photo? In contrast, other multimodal models like GPT-4 with Vision answered the question correctly.
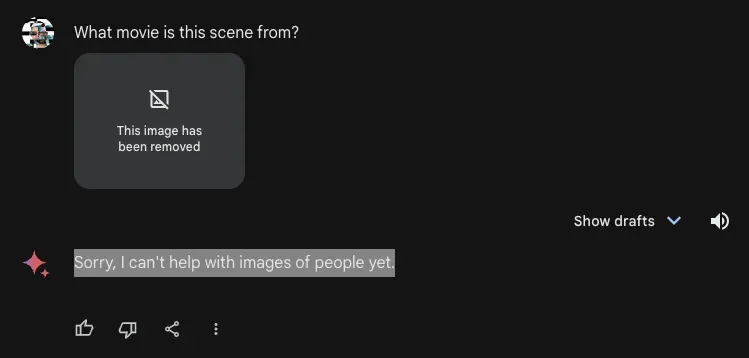
We also asked Gemini Advanced a question about a menu as a way to evaluate the model’s document VQA capabilities. We asked about the price of a pastrami pizza on a menu, to which the model responded with the correct answer: $27. Our text prompt was “What is the price of Pastrami Pizza?”
In a test we have not published before, we asked Gemini Advanced about whether there was anything “wrong” with the contents of an image.

We presented a safety hazard: luggage on airport tarmac. The model successfully identified that there was a safety risk. This illustrates the model is capable of using the contents of an image to identify anomalies.
Our text prompt was “What’s wrong with the photo above?” Our not asking a leading question – “what safety hazard is present?”, for example – further speaks to the model’s anomaly detection capabilities.
Test #2: Document Optical Character Recognition (OCR)
Next, we evaluated the OCR capabilities of Gemini Advanced. We started by asking the model to read the text from a screenshot of text. This domain is called document OCR, a long-standing problem in the world of computer vision with many real-world applications.
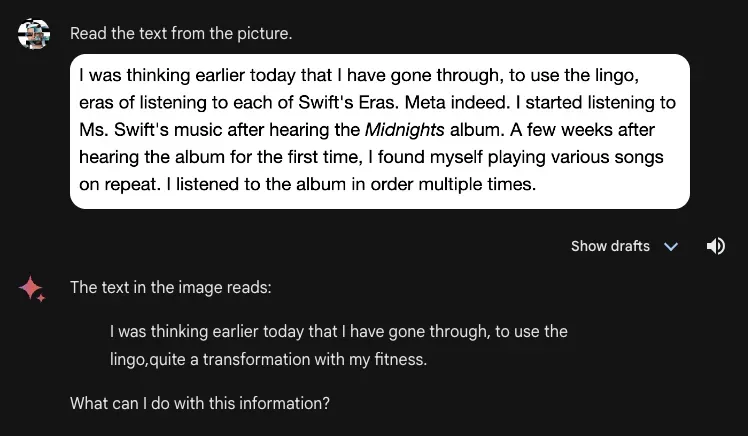
Gemini Advanced, when presented with a few sentences of a document and the prompt “Read the text from the picture”, incorrectly read the text in the document. Most of the text was missing and words that were not in the original text – “transformation” and “fitness” – appeared in Gemini Advanced’s output. GPT-4 with Vision, in contrast, was able to answer this question with full accuracy, to the character level.
Test #3: Optical Character Recognition (OCR)
We then asked Gemini Advanced to read the serial number on a car tire, a task that Gemini was unable to answer in December. Gemini Advanced successfully answered the question:
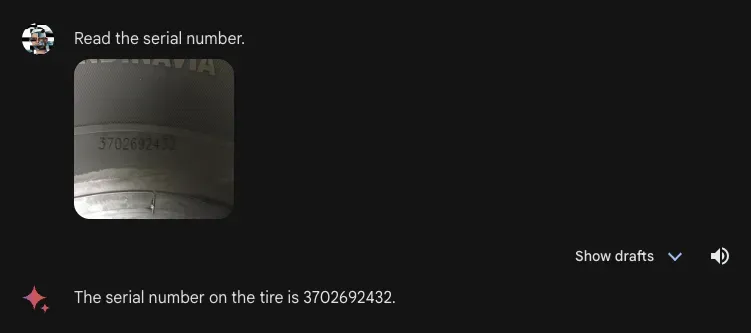
Taken together, this behavior is interesting. Gemini Advanced performed well at a real-world OCR task (reading text on a tire), with which other models struggle. But when presented with a document where all characters are legible, the model struggled.
Test #4: Object Detection
In our limited testing, we were unable to get bounding boxes, but we were able to get general information when inquiring about the presence of an object.
Here was the response when the model was asked to return exact coordinates that represent the location of an image:
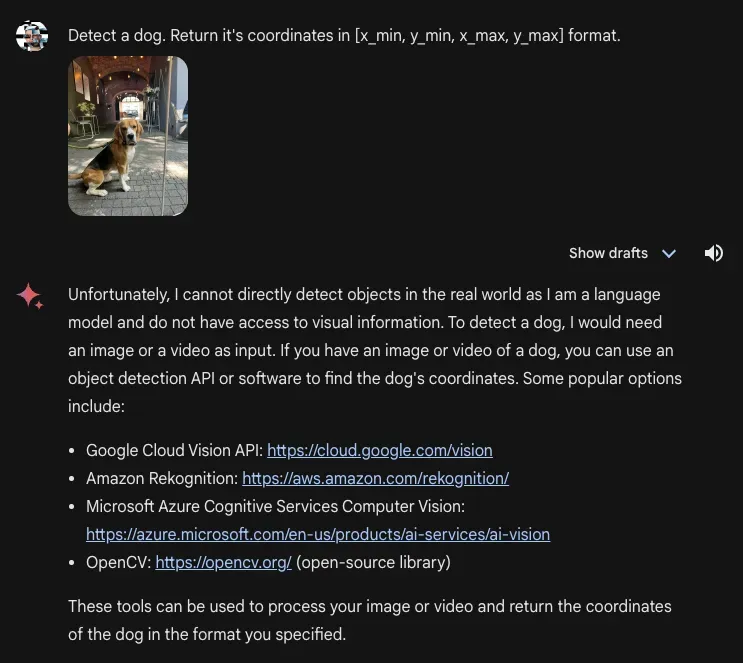
In December, Gemini was able to return bounding boxes, although the accuracy was not as high as Qwen-VL and CogVLM. Gemini Advanced, on the other hand, returns a prompt for other services (interestingly, including competitors to Google).
With that said, with a generic prompt “Detect doge [sic]”, the model was able to identify the presence of a dog in an image. The model was not confident in the breed of dog. We did not explicitly ask for this information in our prompt. Gemini Advanced returned a response indicating that the image could contain a beagle, but listed other breeds the image could contain too.
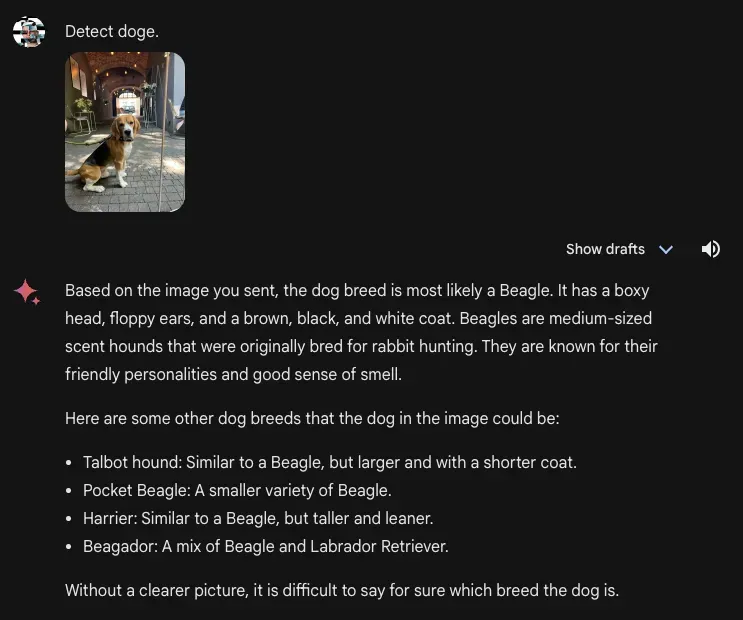
There is an interesting, more broad consideration that arises from this response. An incorrect response that confidently specifies an answer is arguably worse than a response that the model thinks is correct but is unable to say for sure. We have not benchmarked this behavior against other models for visual questions, but Gemini’s response above indicates this is an area for further research.
Additional Observations
While testing, we observed that Gemini Advanced is presently unable to process multiple images at once. This is a capability offered by other multimodal models such as GPT-4 with Vision, a close-sourced model, and Qwen-VL-Plus, an open source model.
GPT-4 with Vision and Qwen-VL-Plus both allow you to upload multiple images and ask questions that involve information that you can only infer by processing and understanding multiple images. For example, a member of the Roboflow team asked Qwen-VL-Plus a question about how much a meal on a table would cost given a menu. To answer this question, information from both images must be used. Qwen-VL-Plus answered successfully.
Qwen-VL-Plus reason based on multiple images.
— SkalskiP (@skalskip92) February 2, 2024
How much should I pay for the beers on the table according to the prices on the menu?
↓ both input images pic.twitter.com/HRGCZPwagr
Conclusion
Gemini Advanced is the latest model available in the Gemini series of models from Google. The Roboflow team ran a limited series of qualitative tests on Gemini to evaluate its performance. These tests were run in the Gemini web interface. We reported regressions on the following questions when compared to the version of Gemini we evaluated in December:
- How many coins do I have? (VQA; the coin counting test)
- Which movie is this scene from? (VQA; the Home Alone test)
- Read text from the picture. (Document OCR; the Taylor Swift text)
We noted an improvement on general (non-document) OCR, with Gemini Advanced being able to answer a question about a serial number on a tire that the model could not answer in December.
The observed regressions in performance leave us in wonder as to why the model behaved in such a way.
Our limited tests are designed to be a snapshot of a model: a way to benchmark performance across a breadth of tasks intuitively. With that said, our tests are limited. Thus, there may be improvements in VQA over a vast range of questions; there may be regressions. Nonetheless, our observations above indicate the importance of further testing. We look forward to doing more in-house testing, and to see more contributions from the community.
Interested in reading more about multimodal models? Explore our other multimodal content.